-
Source
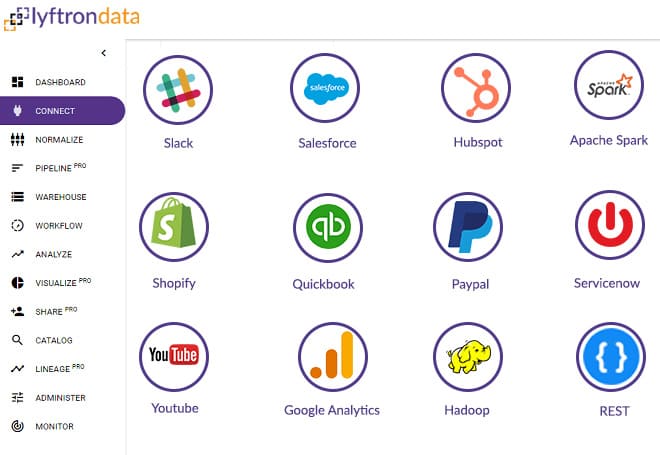
There is nothing easier than connecting your data from different sources to one source and avoid complicated tasks of preparing data and setting up complex ETL processes. This layer ensures a hassle-free process of connecting with source connectors.
-

Virtualization
This layer lies just below “Source” and manages the unified data for centralized security. It provides a common abstraction over any data source type, shielding users from its complexity and back-end technologies it operates on.
-

Caching
This third layer is used to cache data used by SQL queries. Whenever data is needed for a given query it's retrieved from here, and cached in SSD and memory.
-
Metadata
Under the covers of the caching layer, Lyftrondata possesses metadata that works to improve the overall performance capacity. This layer takes care of scheduler, alerts, workflow, data catalog, logs, monitoring, execution plan and more
-
Security
Considered as the heart of Lyftrondata, this layer handles one of the most crucial functions of enforcing security and encrypts key management. This functions for encryption, tagging, masking, access rights and role management.
-
Visualization
This innermost layer allows to analyze, visualize and explore the massive volume of data from disparate data sources, empowering users to drive real-time insights for business decisions.


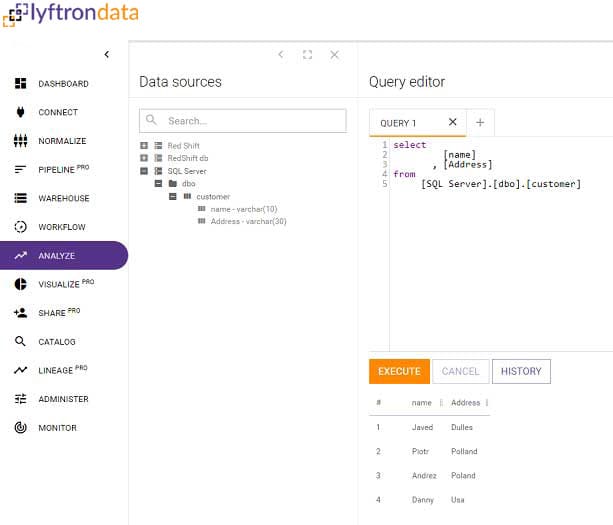
Query API data with SQL familiar syntax
Easily auto-extract JSON, XML schemas into relational format
Emulation compatibility with SQL Server
Secure your sensitive data with our encryption functions

Perform complex transformations

Quickly apply complex joins

Easily query data from S3, Blob, JSON, Xml like a table
Federate data sources like actual database

State-of-the-art facial recognition API








-
 Extract your data
Extract your data
-
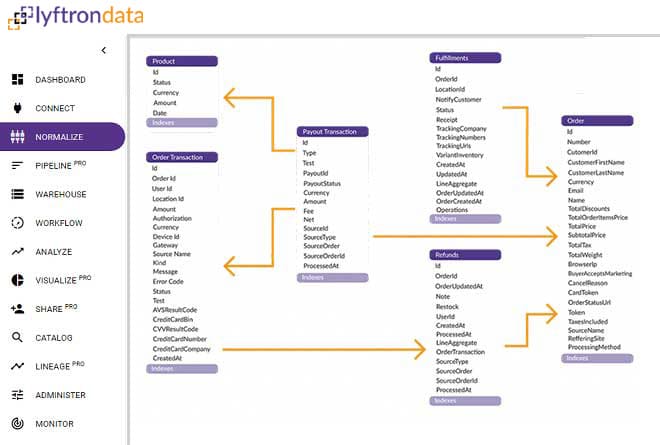
 Auto normalize your data
Auto normalize your data
-
 Analyse your data
Analyse your data
-
 Transformation
Transformation
-
 Visualize your data with BI tools
Visualize your data with BI tools
-
 Share your data
Share your data