-

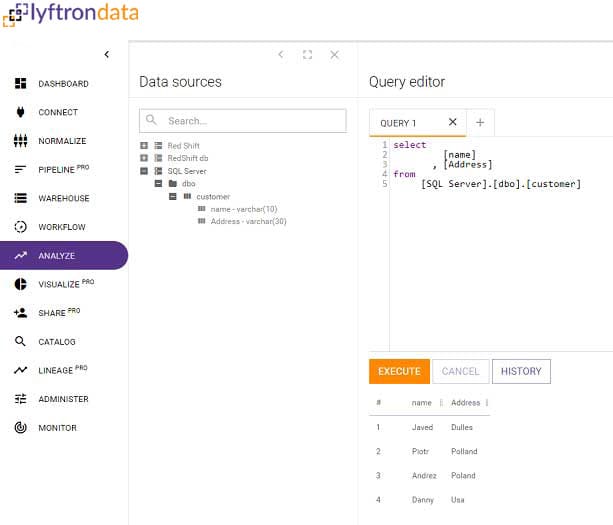
Query with familiar ANSI SQL
Avoid writing lengthy codes, use simple SQL to query any data. Lyftrondata architecture supports automatic zero code JSON/XML/API parsing to relational format and allows users to analyze instantly with ANSI.
-
Simplify data ingestion on S3
Ensure secured streaming of data from varied sources on S3, ensuring your delta lake is always optimized and irrigated with the most recent data sets.
-

Data storage on S3 for lifelong
Forget all the traditional storage hassles, and think only about storing your data, both raw or Parquet/ORC files, on S3 and make it consumption-ready by applying industry best practices.
-

Quickly apply complex joins
Apply high cardinality joins between S3 and database without heavily relying on the BI and data engineering teams to set up complex and time-consuming ETLs.
-
Faster query performance
Load the data in S3 without any delays and without worrying about structure or schema. Data is loaded from the data source, data transformations are applied on the fly as SQL expressions and the transformed data is streamed directly to the warehouse.
-
Unlimited cloud compute
Lyftrondata’s columnar architecture automatically scale to support any amount of data, workloads and applications without requiring data movement, data marts or data copies.

-
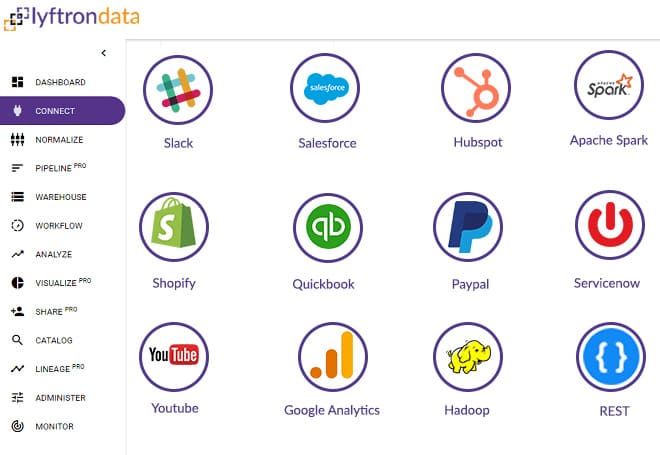
 Extract your data
Extract your data
-
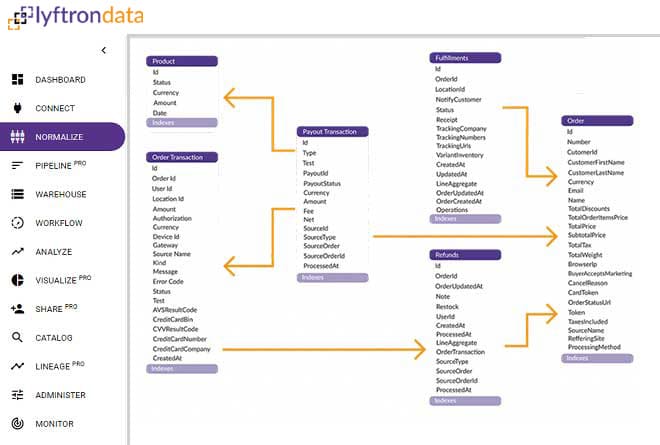
 Auto normalize your data
Auto normalize your data
-
 Analyse your data
Analyse your data
-
 Load your data to warehouse
Load your data to warehouse
-
 Visualize your data with BI tools
Visualize your data with BI tools
-
 Share your data
Share your data