







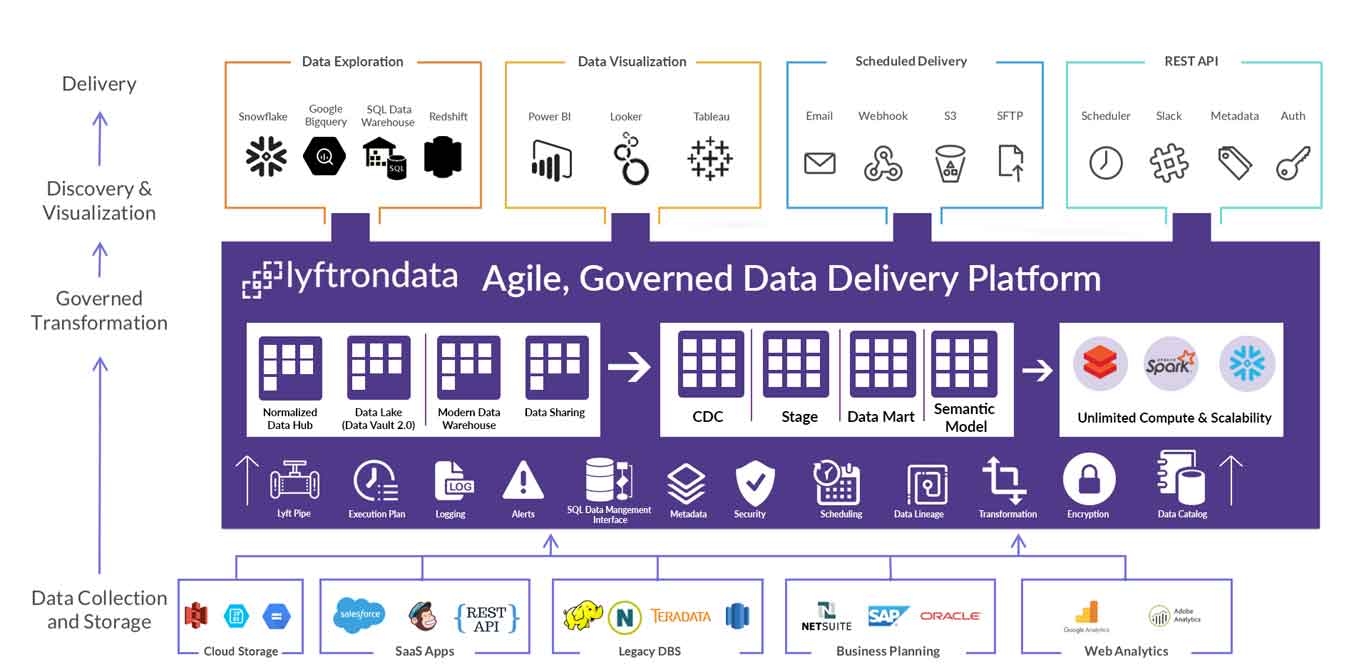













































































































































































































































































































































































































































We make BI and big data analytics work easier and faster. Lyftrondata gives you central view of data from multiple data sources to build modern data pipelines and replication on the fly along with advanced security, data governance and transformation with simple ANSI SQL.
With features like these, we empower data-driven businesses and BI specialists to solve big data issues. Watch the video to learn how we do it!