Integrate your data with Lyftrondata instantly and blend with 150+ other sources
Data extraction with Lyftrondata is easy. Be up and moving in minutes. Without any help from developers, Lyftrondata enables you to choose your most valuable data and pulls it from all your connected data sources in just one click.


Business Analyst
"I feel more aligned with the agile process as now I can analyze any data without worrying about any technical know how. "
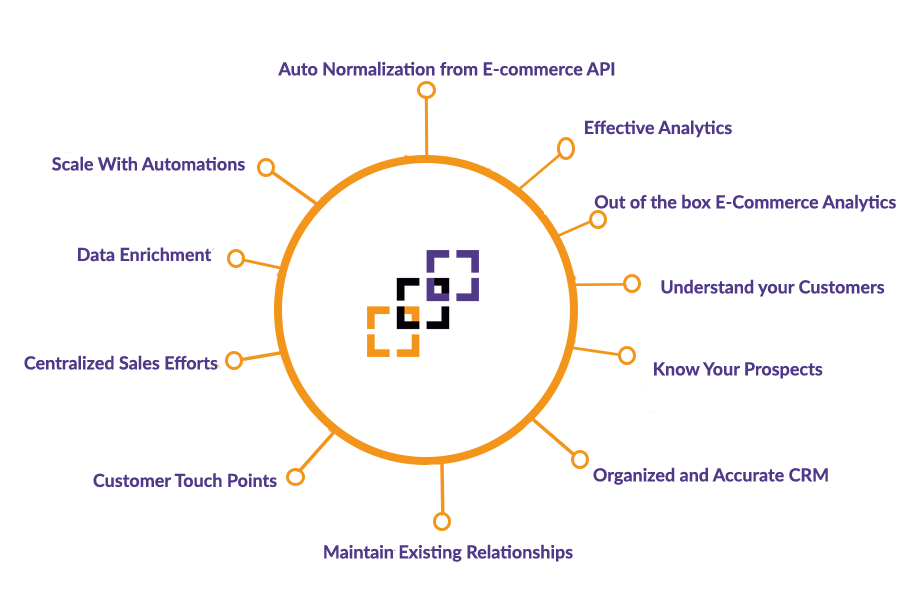
Empower your analytics with out of the box relational data model
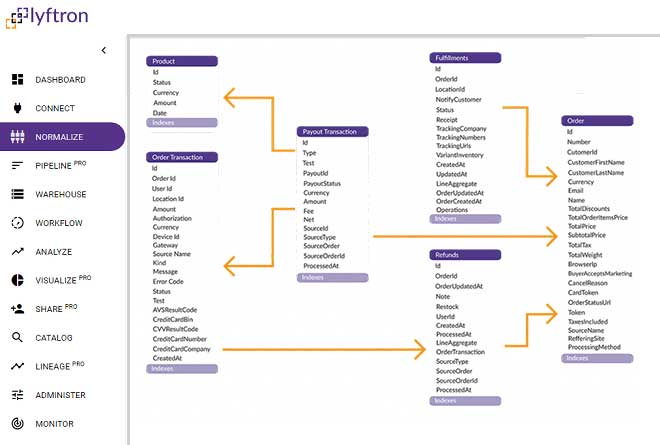
Connect any API, Json, XML and automatically analyze it with ANSI SQL and load it to Snowflake. Once the data is extracted, you could ingest it to Snowflake or BI tool of your choice with zero coding required. Lyftrondata connectors automatically convert any source data into normalized structure of ANSI Sql and push down the data pipeline processing as an ELT to the native cloud data warehouse.

Data Analyst
"I have a better control on the data analysis process as now I can run rapid fast queries against the API’s which I never thought possible."
Built for the agile data culture for your data
Next, analyze massive volumes of this real-time data in visualization tools and get instant answers to your store performance. Over 100 integrations empower you to use your favorite tools to map data, build and visualize custom reports and more.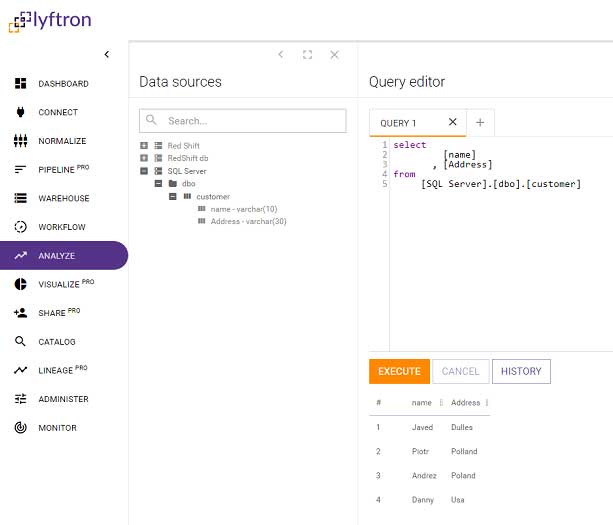

Data Architect
" I am able to do the architecture and requirement gathering by simply writing ANSI Sql queries for the API sources which use to be the taboos for me."
Load your data into your warehouse or lake instantly
Transform your growth metrics by combining your data and your delta automatically. Joining tables, renaming metrics and mathematical calculations result in a deeper and more complex data structure than the raw data.

ETL Developer
" I am able to build my data pipeline in few clicks and load billions of records to my warehouse and also able to do cross platform joins on the API sources with ease."
Load your data into your warehouse or lake instantly
Build delta lake on the Snowflake and save thousands of engineering hours and significantly reduce total cost of ownership. The platform handles all the infrastructure development, empowering users to skip engineering work and go straight to analysis.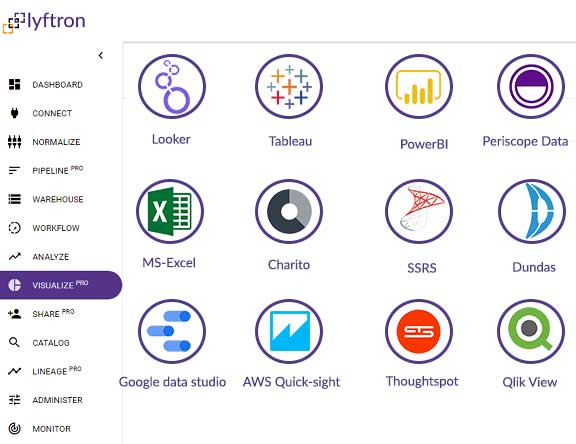

BI Analyst
" I have a better response from the BI reports and able to connect with API/Json/XML based sources in just fewer clicks. "
Data sharing is data caring
Define, categorize and find all data sets in one place. Share these data sets with other experts through APIs and drive better insights and user experience. This data sharing ability is perfect for companies who want to store their data once, share it with other experts and use it multiple times, now and in future.

Our Agile Team
" We are in full control of our data exchange process and easily able to share the data instantly and collaborate with teams with ease without worrying about writing complex API, FTP, Email for data sharing. "
-

Snowflake processing for faster query performance
Lyftrondata allows enterprises to easily process data and incremental changes from multiple sources to Snowflake. With the most cost-effective licensing model, it empowers data analysts with real-time insights and data security through advanced encryption.
-
Secured and seamless data sharing
Lyftrondata and Snowflake follows best-in-class, standards-based practices to ensure your data and data warehouse security. Lyftrondata enables data masking and encryption to handle your sensitive data.
-

Lower infrastructure costs
Lyftrondata’s architecture lowers infrastructure costs and reduces network load by eliminating the need for separate staging infrastructure or servers. The platform controls the existing power of DBMS hardware engines, rather than depending on external staging servers & scale with ease.
-

Codeless development environment and integrated metadata views
Lyftrondata is equipped with the most intuitive and user friendly interface. Within a couple of clicks, you can load, transfer and replicate data to any platforms without any hassle. Do not worry about codes or scripts.
-

Unlimited cloud compute
Lyftrondata and Snowflake columnar architecture automatically scale to support any amount of data, workloads and concurrent users and applications without requiring data movement, data marts or data copies.
-
Data integration
Connect 130+ on-premise and cloud data sources and set up continuous data synchronization of selected data to Amazon Redshift, Snowflake, Azure SQL DW or any other database.
-

Business intelligence at your fingertips
Connect any BI tool using build-in SQL Server drivers through a fully simulated SQL Server protocol. Bridge a connection from SaaS BI tools to on-premise data and the on-premise Enterprise Data Warehouse.