Data virtualization for data-driven enterprises: a game-changer and revenue generator
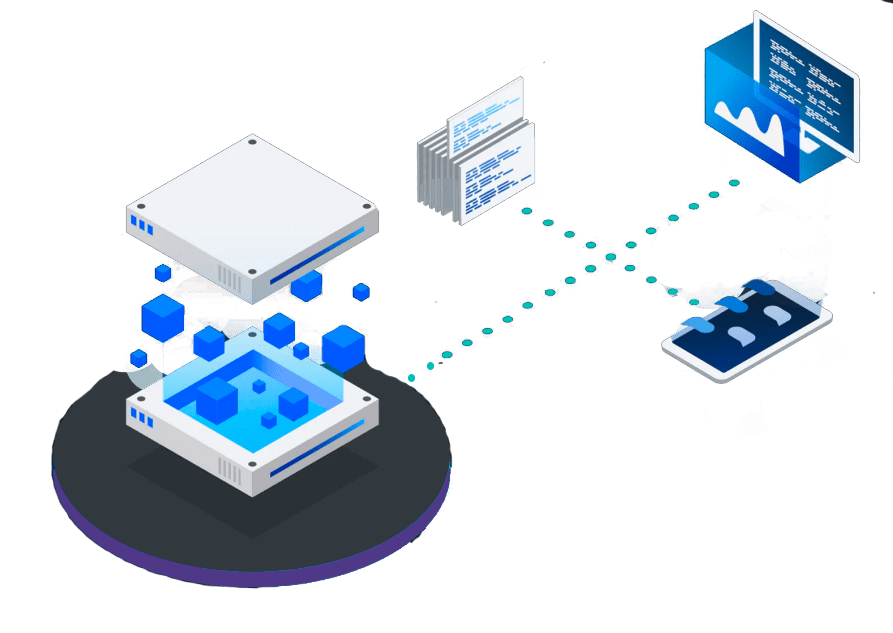
Modern Data virtualization for greater speed, agility, and response time
In today’s data-driven economy, businesses need to be able to integrate, manage, and access data from multiple sources quickly and easily. Data virtualization is a game-changing technology that allows businesses to do just that, irrespective of the physical location of the data. With Data virtualization, businesses can increase efficiency, agility, and scalability while reducing costs.
Data virtualization with Lyftrondata
Data virtualization with Modern cloud data warehouses


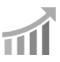


Business benefits of Data virtualization with Lyftrondata
This encapsulates critical information from the outside world and ensures users can’t change the data intentionally.
It’s faster and cheaper to maintain data than it is to replicate and spend resources transforming it into different formats and locations.
Replication requires some serious energy and costs. With Lyftrondata's "zero replication" approach, avoid investing in additional storage and resources.
By delivering data in real-time, Lyftrondata empowers business clients to get to the most present information during standard business operations.
With Lyftrondata's single virtual data texture, Data virtualization enables architects to enforce centralized data administration and security.
Lyftrondata acts as a data layer for analytics that combines traditional data loading with logical data warehousing to improve collaboration and deliver data-driven results needed to handle today's data volumes.
Take a leap from data federation technology and focus on performance optimization as well as self-service search and discovery. Spend more time analyzing data than searching for it.
Data consumers access real-time information of a huge volume of data coming from any source, at any time, and get a holistic view of their enterprise for critical decision making
Connect the semantic contrasts of unstructured and organized data with modern data architecture, and develop immediate access to all the data required for actionable insights.
How it works
Get started in minutes, not months with these agile steps. Zero coding & zero setups required.
-
 Extract your data
Extract your data
-
 Auto normalize your data
Auto normalize your data
-
 Analyse your data
Analyse your data
-
 Virtualize
Virtualize
-
 Visualize your data with BI tools
Visualize your data with BI tools
-
 Share your data
Share your data
Integrate your data with Lyftrondata instantly and blend with 150+ other sources
Data extraction with Lyftrondata is easy. Be up and moving in minutes. Without any help from developers, Lyftrondata enables you to choose your most valuable data and pulls it from all your connected data sources in just a few click.

Business Analyst
Empower your analytics with out-of-the-box relational data model
Once the data is extracted, you could ingest it to the data warehouse or BI tool of your choice with zero coding required. Lyftrondata connectors automatically convert any source data into a normalized structure of ANSI SQL and push down the data pipeline processing as an ELT to the native cloud data warehouse.
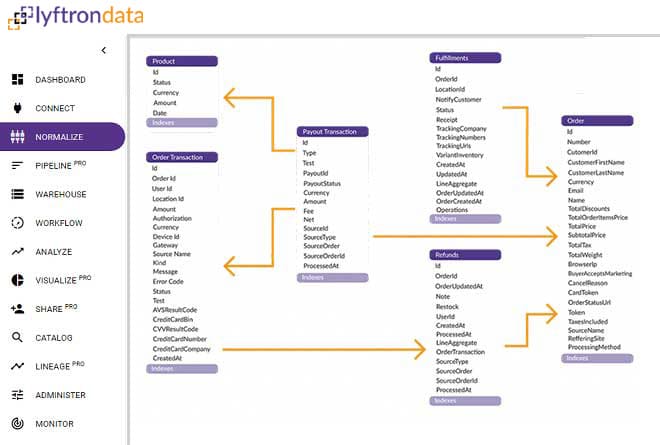

Data Analyst
Built for the agile data culture for your data
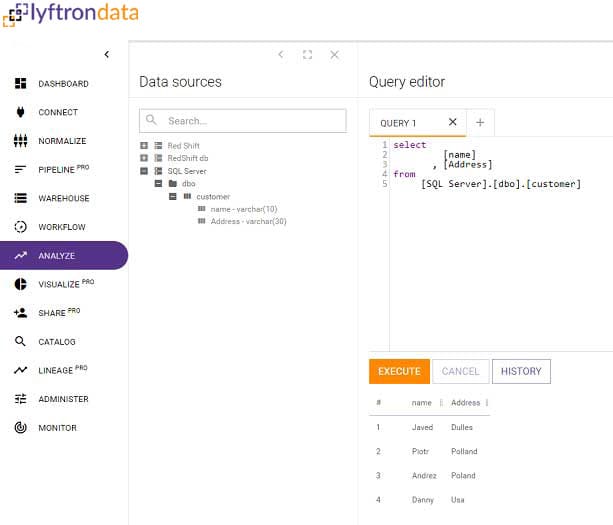

Data Architect
Run SQL queries and virtualize your data instantly.


ETL Developer
Analyze your data from any BI/ML tools


BI Analyst
Data sharing is data caring
Define, categorize and find all data sets in one place. Share these data sets with other experts with zero code and drive better insights and user experience. This data sharing ability is perfect for companies who want to store their data once, share it with other experts and use it multiple times, now and in the future. We build the best data sharing process around your data stack. So say goodbye to the complex API, FTP and Email manual data sharing processes and simply onboard your consumers to the Lyftrondata platform in just a few minutes.


Our Agile Team
Know the heart and soul of Data Virtualization with Lyftrondata
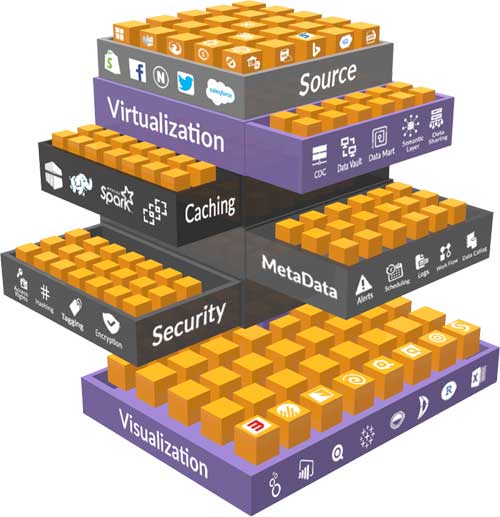
There is nothing easier than connecting your data from different sources to one source and avoid complicated tasks of preparing data and setting up complex ETL processes. This layer ensures a hassle-free process of connecting with source connectors.
This layer lies just below “Source” and manages the unified data for centralized security. It provides a common abstraction over any data source type, shielding users from its complexity and back-end technologies it operates on.
This third layer is used to cache data used by SQL queries. Whenever data is needed for a given query it's retrieved from here, and cached in SSD and memory.
Under the covers of the caching layer, Lyftrondata possesses metadata that works to improve the overall performance capacity. This layer takes care of scheduler, alerts, workflow, data catalog, logs, monitoring, execution plan and more.
Considered as the heart of Lyftrondata, this layer handles one of the most crucial functions of enforcing security and encrypts key management. This functions for encryption, tagging, masking, access rights and role management.
This innermost layer allows you to analyze, visualize and explore the massive volume of data from disparate data sources, empowering users to drive real-time insights for business decisions.
Data virtualization for all
Focus on delivering results at minimal risk rather than managing your data. Gain real-time data access to make timely decisions, and improve campaign performance, all while saving money.
With Lyftrondata's Data virtualization, SMEs could save 50-80% cost, time and effort over traditional integration methods. It is more agile and focuses on nothing but ROI.
Use the modern data architectures to abstract the complexity of accessing data from disparate data sources. Have strict control of who accesses your data, at what time.
Focus only on building the application with a zero coding platform at negligible risk. Save heaps of cost and time and deliver at scale and velocity.
Deliver sales reports and improve campaign performance with real-time data access. Predict customers' behaviour and make timely decisions to achieve phenomenal retention and growth.
Empower BI analysts to integrate data from disparate sources of their choice and drive actionable insights from fresh, real-time information, all of this without relying on the technical team.
Based solely on principles of security management, data governance and performance optimization, Lyftrondata's Data Virtualization ensure every data flowing is under the secured and safe ecosystem.
What you get
Query API data with SQL familiar syntax
Easily auto-extract JSON, XML schemas into relational format
Emulation compatibility with SQL Server
- Metadata model exposed by SQL Server, including metadata catalog, system views, stored procedures, and functions.
- SQL dialect supported by SQL Server.
- Tabular Data Stream network protocol as described in Microsoft TDS documentation.
- Data types and conversions, where all data types are normalized automatically into equivalent SQL Server data types.
Secure your sensitive data with our encryption functions
Perform complex transformations
Quickly apply complex joins
Easily query data from S3, Blob, JSON, Xml like a table
Federate data sources like actual database
State-of-the-art facial recognition API
Other products
FAQ
Lyftrondata is a high-performance data virtualization solution for immediate data access, quick data centralization and data governance. Its next-gen architecture complements processes like data warehousing, data preparation, data quality management, and data integration for the highest possible performance.
It empowers enterprises to build a single source of data truth by using a virtual layer on their data environment, thereby providing real-time data access for faster decision making.
Architects could use this to abstract the complexity of accessing data and developers , to build applications quickly and easily, with zero coding environment.
Data virtualization with Lyftrondata makes the data available in minutes and automates data workflows using SQL, thereby cutting down the development, cost, time and efforts by 80%.
Focused on improved transparency and accountability, the modern architecture encapsulates critical information from the outside world and ensures users can’t change the data intentionally.
The modern data platform eliminates the time spent by engineers building data pipelines manually, and makes data instantly accessible by providing real-time access with simple ANSI SQL. Lyftrondata’s prebuilt connectors automatically deliver data to warehouses in normalized, ready-to-query schemas and provide full search on data catalog.
Please Click here or write to us at [email protected] for details related to pricing.

Satisfy your thirst for better data outcomes.
What challenges are you trying to solve?
Awards





