Lyftrondata recently conducted a poll to hear about the best cloud data warehouse. Read more !


The Logical Data Warehouse as a transmission and processing layer for IoT
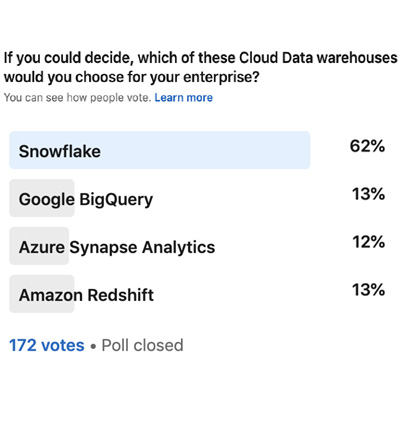
Lyftrondata recently conducted a poll to understand which cloud data warehouse is dominating the industry and the hearts of people. With more than 8000 views and 172 votes, Snowflake emerged as the highest-rated, top-performing, cloud data warehouse.
The poll simply asked the audience to click on their preferred cloud data warehouse, and Snowflake topped the charts with a whopping 62% audience votes! Google BigQuery and Amazon Redshift ranked second with 13%, followed by Azure Synapse Analytics which received 12%. Let us now learn about Lyftrondata and Snowflake, and how together they perform productive and reliable functionalities.
Lyftrondata is a next-generation “No-Code/Low-Code” agile data delivery platform that allows the user to create and manage all their data workloads in one platform, and easily analyze the data instantly with ANSI SQL, BI, and ML tools. Lyftrondata provides self-service capabilities for data engineers and analysts, enabling them to:
Data Virtualization with Lyftrondata a game changer and revenue generator
Snowflake delivers the Data Cloud — a global network, where thousands of organizations mobilize data with near-unlimited scale, concurrency, and performance. Inside the Data Cloud, organizations unite their siloed data, easily discover and securely share governed data, and execute diverse analytic workloads. Wherever data or users reside, Snowflake delivers a single and seamless experience across multiple public clouds. Snowflake’s platform is the engine that powers and provides access to the Data Cloud, creating a solution for data warehousing, data lakes, data engineering, data science, data application development, and data sharing.
A fast, no-fuss data warehouse as a service, Snowflake scales dynamically to give you the performance you need, exactly when you need it. Its architecture separates compute from storage, so you can scale up and down on the fly without delay or disruption even while queries are running. You get the performance you need exactly when you need it, and you pay only for the computer you use. Snowflake’s adaptive optimization ensures queries get the best automatic performance possible, with no indexes, distribution keys, or tuning parameters to manage. Snowflake can support unlimited concurrency with its unique multi-cluster, shared data architecture.
Key Highlights:
- The snowflake architecture allows storage and computes to scale independently.
- Sharing functionality makes it easy for organizations to collaborate effectively.
- You can clone a table, a schema, or even a database in no time.

Snowflake data exchange
Explore the Materialized View of Snowflake in detail. Read the blog to learn it in indepth.

An Overview of the Materialized View of Snowflake
Securely Transferring Sensitive Data Between Clouds Read the customer story of Lyftrondata and explore how
The extra disk space required for data loading to Snowflake emerged as a major bottleneck to the data pipeline. Lyftrondata utilizes the data streaming API of Snowflake to enable a unique approach to data loading into the Snowflake Data Warehouse. Data is loaded from the data source, then data transformations are applied as SQL expressions, and the transformed data is streamed directly into Snowflake. Data loading thus happens quickly without any need to manage space for the temporary files. To reduce the amount of data that must be transferred, Lyftrondata pushes down the selected SQL transformations directly to data sources.
Lyftrondata connects directly to a Snowflake Data Warehouse and normalizes the data, which enables simple query capability. Moreover, Lyftrondata allows data virtualization capabilities over a Snowflake data warehouse which facilitates users to easily do cross-platform analysis between Snowflake and other data providers like API, relational databases, NoSQL, other cloud data warehouses, CRM, ERP, and more.
Lyftrondata, also, allows data sharing capabilities so users can invite consumers on the platform and assign them access to the database, schema, table, or columns.
Lyftrondata connects directly to a Snowflake Data Warehouse and normalizes the data, which enables simple query capability. This allows the customer to analyze the data from a centralized transformed data repository.
Lyftrondata can then have a REST Application Programming Interface (API) that allows the end-user to access the Snowflake data that is stored in the user’s Lyftrondata account over REST protocol and to query all the tables as a JSON.
Lyftrondata allows data virtualization capabilities over a Snowflake data warehouse which facilitates users to easily do cross-platform analysis between Snowflake and other data providers like API, relational databases, NoSQL, other cloud data warehouses, CRM, ERP, and much more.
Lyftrondata allows data governance capabilities on the Snowflake data so users can apply access rights as granular as column-level based on the user or roles and also apply row-level encryption based on the sensitivity of the data.
Lyftrondata allows data catalog and lineage capabilities on the Snowflake cloud data warehouse by enabling users to tag the objects like schema, table, database, column, pipeline, etc., and let you search the metadata based on your use case.
Lyftrondata allows data sharing capabilities so users can invite consumers on the platform and assign them access to the database, schema, table, or columns. Users can login to the Lyftrondata platform and simply analyze the data. They can also build the data pipeline to load the transformed data into their centralized environment.










