

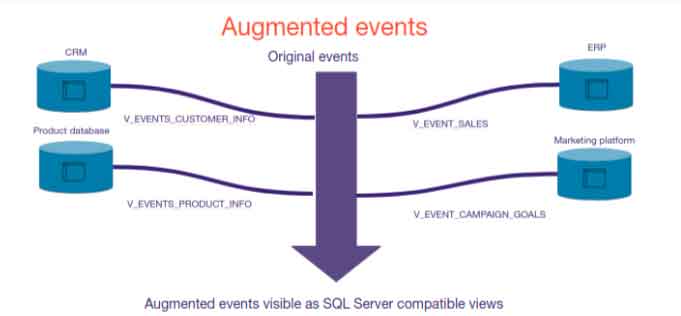
A mountain of data…. two architectures
These sensors generate a great volume of data that can only be used one time. The problem with IoT is not the same as with Big Data. No storage speed is required as these data will lose their value within a few days. In other words, device data is sent out as an endless stream of raw events that require rapid interpretation by the processing layer. The events contain basic information such as device identification, action, date and time. To achieve certain business objectives it is necessary to efficiently manage queries by interacting with data storage. This is why there are two important data processing architectures that serve as the backbone of IoT applications: Lambda and Kappa.
Lambda Architecture
Lambda architecture is a data processing technique that is capable of handling large amounts of data efficiently. The efficiency of this architecture is evident in the form of higher performance, lower latency and negligible errors.
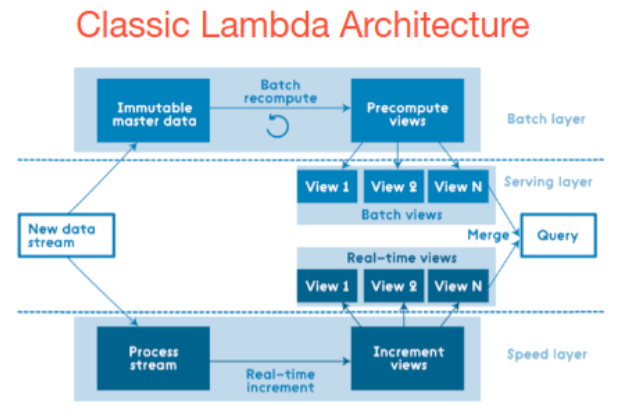
How it works: Events are processed in two separate pipeline, a velocity layer uses a streaming pipeline engine of events such as Apache Flink or Apache Storm. Normally there is a batch layer that is usually a Hadoop cluster with a copy of all events stored in HDFS or S3 and the events are processed in batches. The most important feature of this architecture is that a separate “speed layer” allows for real-time reaction to events. Now we see some points:
- Two similar implementations of complex event detection must be implemented using different tools.
- Not all use cases require a real reaction in real time, a human being can take action when an event is detected, but a person can be busy and take action an hour later so possible human interaction is limited.
- When using Lambda
When user queries are required to be handled ad-hoc using immutable data storage. - When quick responses are required and the system must be able to handle multiple updates in the form of new data streams at once.
- When none of the stored records should be deleted and updates and new data need to be added to the database. (information over time does not lose value).
Kappa Architecture
A discussion began in 2014 by Jay Kreps in which he pointed outsome discrepancies in lambda architecture that led some specialists to an alternative architecture that used fewer code resources and was able to work well in certain business scenarios where the use of multiple layers of lambda architecture did not seem the best solution.
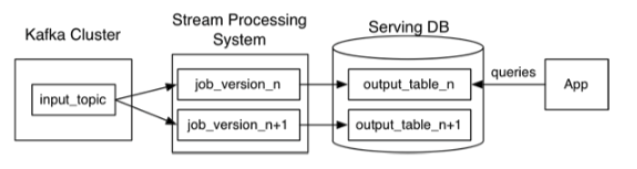
Kappa Architecture cannot be considered a substitute for lambda architecture, but rather an alternative to be used in circumstances where the active performance of the load layer is not necessary to meet the quality of service. This architecture
finds its applications in the real-time processing of different events. Here are some features:
- Implementation is much easier without duplicating the complex event detection logic.
- Applicable in applications that involve a human reaction and do not require a real reaction in real time as a batch detection of events every 10 minutes is sufficient.
- Batch processing of events on a large data platform (such as Querona) allows for more options to relate or link events to internal company data and this data must be provided in some way (this is where Querona helps).
- Multiple data events or queries are logged in a queue to be handled against a distributed or historical file storage system.
- Sequence processing platforms can interact with the database at any time as the order of events and queries is not predetermined.
- The architecture is robust and highly available, requiring Terabytes of storage for each node of the system to support replication.








