Destination
The destination is the first consideration. It signifies where the data needed and why. Datastores – data warehouses, data lakes, data marts, or lake houses are common destinations of a pipeline. Applications may also be another destination for pipelines to take on tasks such as machine learning model training/applying etc.
Origin
Origin considerations are often driven by datastore design. Data should be where it makes the most sense to optimize transactional performance/storage cost or improve latency for near real-time pipelines. Transactional systems should be considered as an origin if they provide reliable and timely information needed at the pipeline’s destination(s).
Dataflow
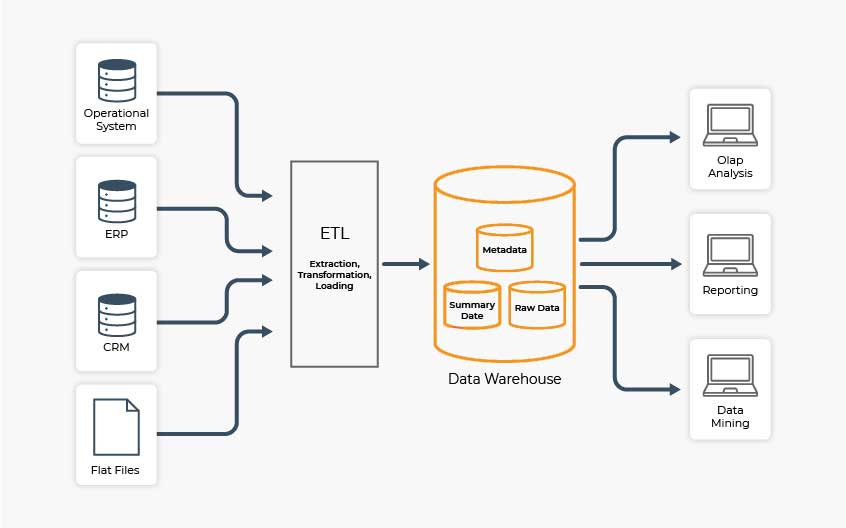
Dataflow is the sequence of processes and stores that data moves through as it travels from source to endpoint. Dataflow is a part of an overall pipeline’s design process which involves much consideration when designing pipelines.
Storage
Storage refers to the systems where intermediate data persists as it moves through the pipeline and to the data stores at pipeline endpoints. Storage options include relational databases, columnar databases, key-value stores, document databases, graph databases, etc. The volume of data often determines storage type but other considerations can include data structure/format, duration of data retention, uses of the data, etc.
Processing
Processing refers to the steps and activities performed to ingest, transform, and deliver data across the pipeline. By executing the right procedures in the right sequence, processing turns input data into output data. Ingestion processes export or extract data from source systems and transformation processes improve, enrich, and format data for specific intended uses. Other common data pipeline processes include blending, sampling, and aggregation tasks.
Workflow
Workflow refers to the sequence of processes and data stores. Pipeline workflows handle sequencing and dependencies at two levels–the level of individual tasks performing a specific function, and the level of units or jobs combining multiple tasks. Data flows through pipelines in much smaller batches than it would when streaming from real-time sources. Some pipelines may only contain one task, while others may include many tasks connected by dependencies and data transformations to get from source to endpoint/destination(s).
Monitoring
Monitoring involves the observation of a data pipeline to ensure efficiency, reliability, and strong performance. Considerations in designing pipeline monitoring systems include what needs to be monitored, who will be monitoring it, what thresholds or limits are applicable, and what actions will be taken when these thresholds or limits are reached.
Alerting
Alerting systems inform data teams when any events requiring action occur in a pipeline. Alerting systems include email, SMS alerts, etc.