



Learn about Feature Store, which is an emerging concept in AI and advanced analytic, and why Data Virtualization is one of the best options for Feature Store as a Service (FSaaS).
Feature Store is a hot topic in today’s AI and Advanced Analytics and a lot of vendors are actively looking into it and are working on solutions and products to fulfill the requirements. Before explaining data virtualization as a good fit for FSaaS, let’s explain a feature first.
Feature
Even though “feature” is a more common word in AI and advanced analytics, but a feature is essentially a form of data that is built based on raw or existing feature(s). A new form of data used to be generated by integration, ETL, RPA tools, etc, however, the common understanding is that features are those forms of data that are generated by feature engineering processes and are meant to be used by AI services. When we look at some real feature implementations, we can see that not all features are too complex or specific to AI, and most of the time, the same features can be used for integration, analytic, or reporting also.
A feature, regardless of its feature engineering complexity, can be an enterprise data asset and may have other consumers than only AI. Therefore, if it turns out to be an enterprise asset, it still needs a centralized repository, data catalog, and governance and must be sharable to authorized people/systems.
Now let’s look at some examples of feature generation:
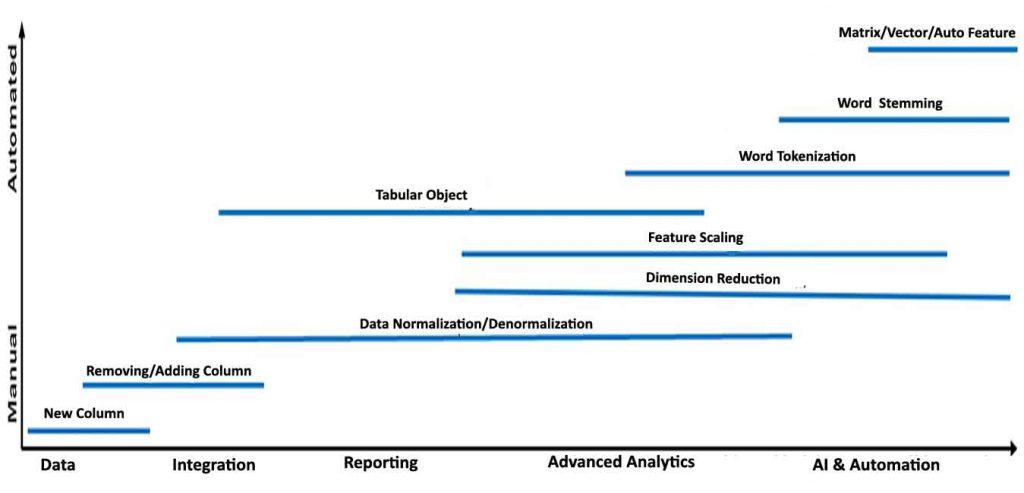
- Creating new column(s), updating/removing existing columns of existing raw data/feature(s)
- Feature normalization / feature scaling / dimension reduction / outliers & anomalies, etc of existing raw data/feature(s)
- Creating a new tabular object (table, view, materialized view, CSV, etc), a new unstructured object (blob, text, JSON, etc), and new semi-structured object (No-SQL, graph, etc) from existing raw data/feature(s)
- AI algorithm object like matrixes, vectors, auto-generated features etc


More about the feature
Feature purpose
The reason for generating a feature is important, as that explains the position of a feature in the feature spectrum (next item). A feature is generated for the below purposes:
Feature spectrum
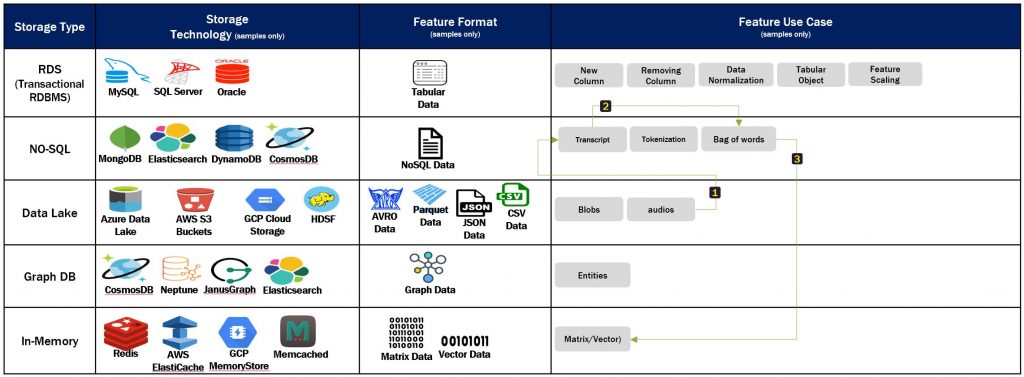
Feature storage
Feature engineering tool
Feature configuration
What we learn from all the above contexts are
- A feature is not necessarily an AI object and can be a widespread enterprise data asset
- Feature store is better to be decoupled from any storage technology and feature engineering tooling
- Feature store is better to provide capabilities like configuration, governance, security, sharing, etc
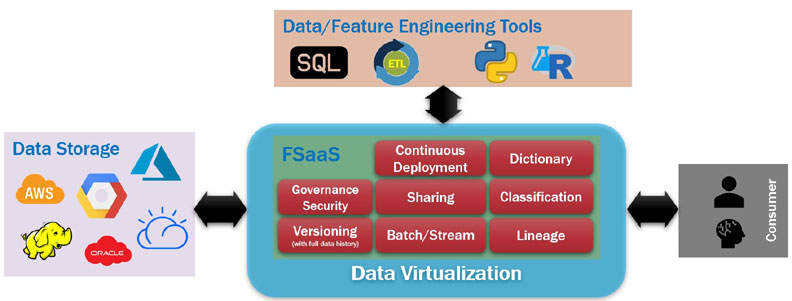
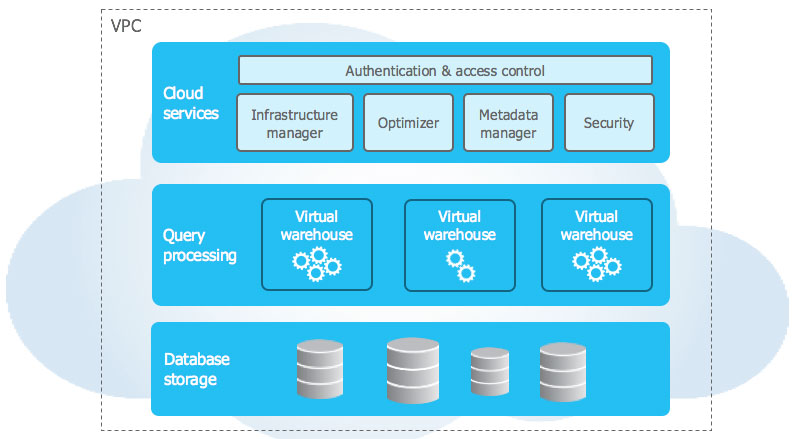
Data virtualization
- Data Virtualization generates virtual data objects (VDOs) based on any data source from anywhere and it decouples itself from storage technologies, whether source or target!
- Data Virtualization is essentially a No-ETL concept but can be used/accessed by all T-SQL, ETLs, programming languages/scripts/tools, visualization tools, and AI platforms, either through virtualization platform, API, or ODBC, which makes it decoupled from tooling.
- Data Virtualization acts as a real data hub and all VDOs are accessible by authorized systems/people.
- All VDOs are governed and secured through a centralized process.
- As VDOs are logical, data catalog and metadata get automatically generated by creating/updating a VDO.
- It is AI-oriented
- It has a local storage that can be an issue from a data security and governance point of view and it is not supporting all data types
- It is not part of an enterprise data platform that makes enterprise usability of its feature impossible
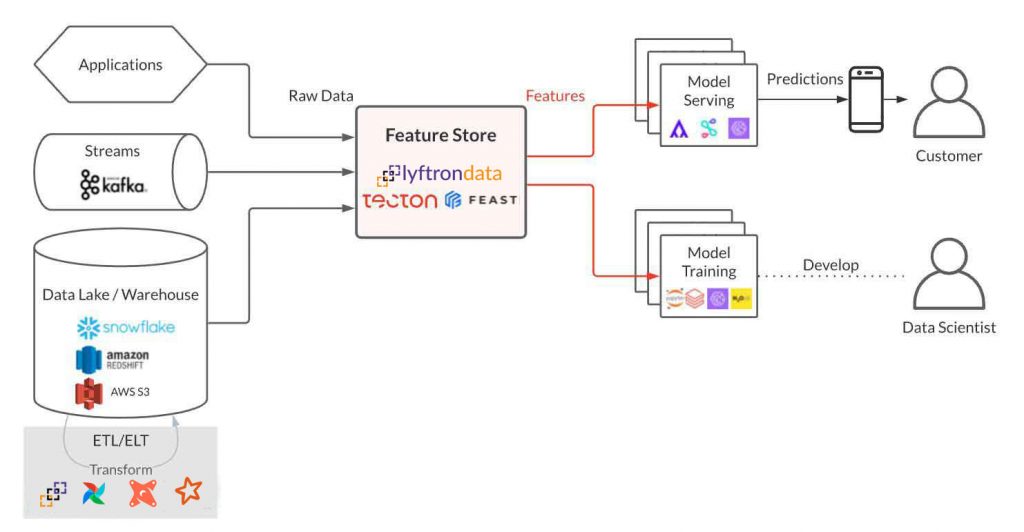
- It is a centralized data repository and not a distributed platform, so it is not able to generate cross-platform features
- It binds its engine to one of the cloud providers and it is not a cloud-agnostic platform
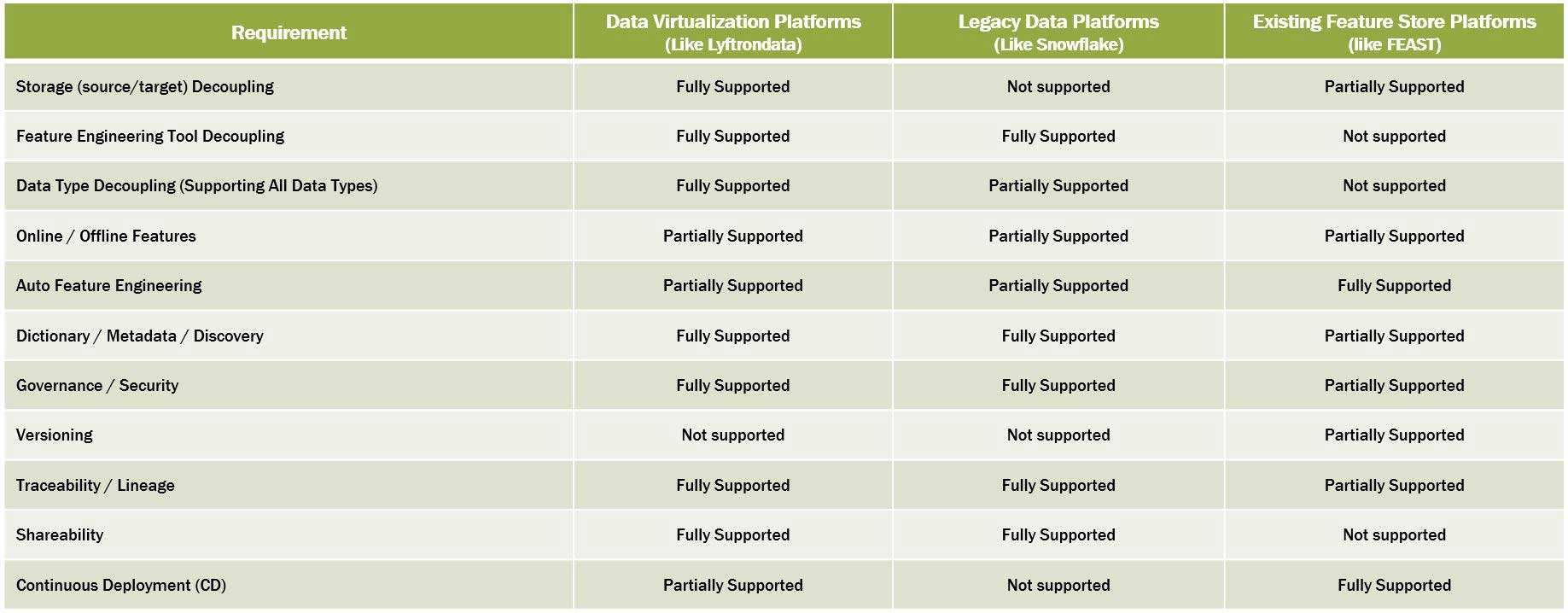
Disclaimer: Bear in mind that, I tried to have a fair comparison based on my own experiences, my definition of feature store and common market tools & platforms which I have seen and been working with, but if I missed something or new works are going around, I would be happy to get your feedback through my LinkedIn, please.
 Ali Aghatabar, founder and director of Intelicosmos®, has been helping clients across the globe, particularly the APAC region, for over two decades. With a consulting background, he helped a wide range of clients and industries with their IT needs especially on data & analytic, cloud architecture and computing, AI and process automation, digital transformation, IoT and smart devices, etc.
Ali Aghatabar, founder and director of Intelicosmos®, has been helping clients across the globe, particularly the APAC region, for over two decades. With a consulting background, he helped a wide range of clients and industries with their IT needs especially on data & analytic, cloud architecture and computing, AI and process automation, digital transformation, IoT and smart devices, etc.







