Caching and partitioning
Lyftron supports a few modes of caching and partitioning of your data. Both properties are configured per view.
Caching means that for query processing, Lyftron uses data from the cache instead of reaching out to the source database. It is especially efficient to cache data that is time and resource consuming to gather. On the other hand, caching means that data is only as current as of last cache load.
Newly created cache is initially empty, and it needs to be populated. Depending on the mode used, cache population is one of the following:
- lazy, initialized at first call for cached data,
- on-demand, using a scheduled job or manual stored procedure call.
A partition is a division of data into distinct independent parts using some consistent rule (partitioning key). In other words, data is stored and processed in blocks called partitions.
Partitioning may substantially increase performance when:
- processing can skip partitions; for example, billing data is partitioned by the country code, and query requires processing data for one particular country. In that case, only one partition will be processed.
- processing can be parallelized; for example, query requires grouping by country, and that can be done in parallel for each country partition.
Basic usage
Initially, views are not cached nor partitioned. To start using caching, you need first to configure caching and partitioning.
In-memory cache is populated on the first usage (lazy initialization). To make sure data is cached consult 'Cached' column on 'Tables & views' page.
The following scenario assumes that Apache Spark is used as a virtual database back-end.
-
Go to Databases, select database and then view for which you wish to configure caching and partitioning.
-
While in view details, go to Caching & Partitioning tab.
-
Click 'Edit' and select caching mode, then partitioning mode if necessary or 'No partitioning'.
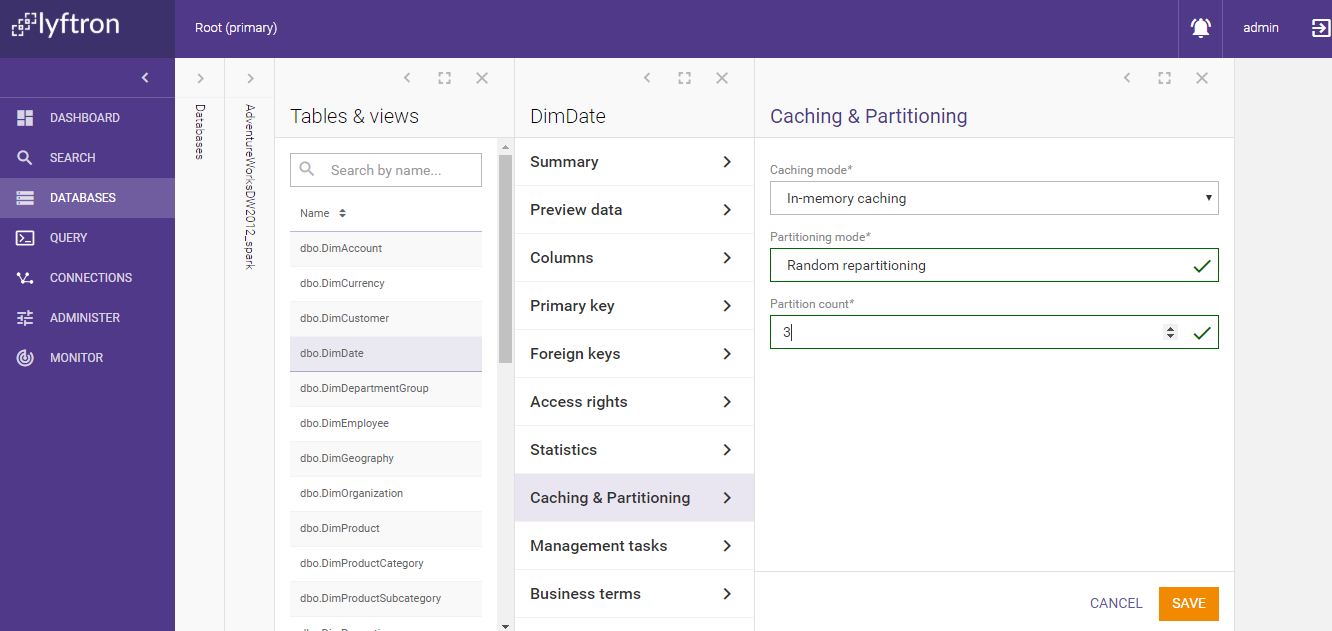
-
Click 'Save'. Caching and partitioning is now configured, but the cache is not yet populated.
-
Go to 'Management Tasks' tab.
-
If the persistent cache was selected, click 'Rebuild persistent cache'. If the in-memory cache was selected, click 'Refresh Spark in-memory cache.' Then click 'Run once' button, to populate the cache. (Strictly speaking, the in-memory cache would be reloaded on the first usage if it was not loaded previously)
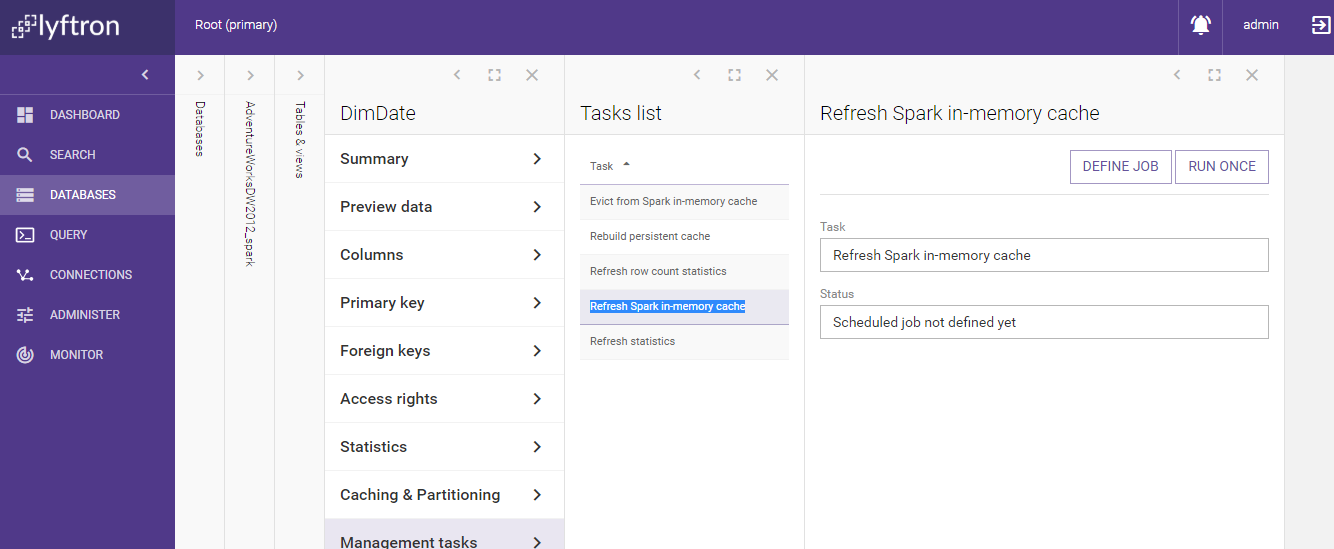
-
After a while, Lyftron will confirm that cache was populated.
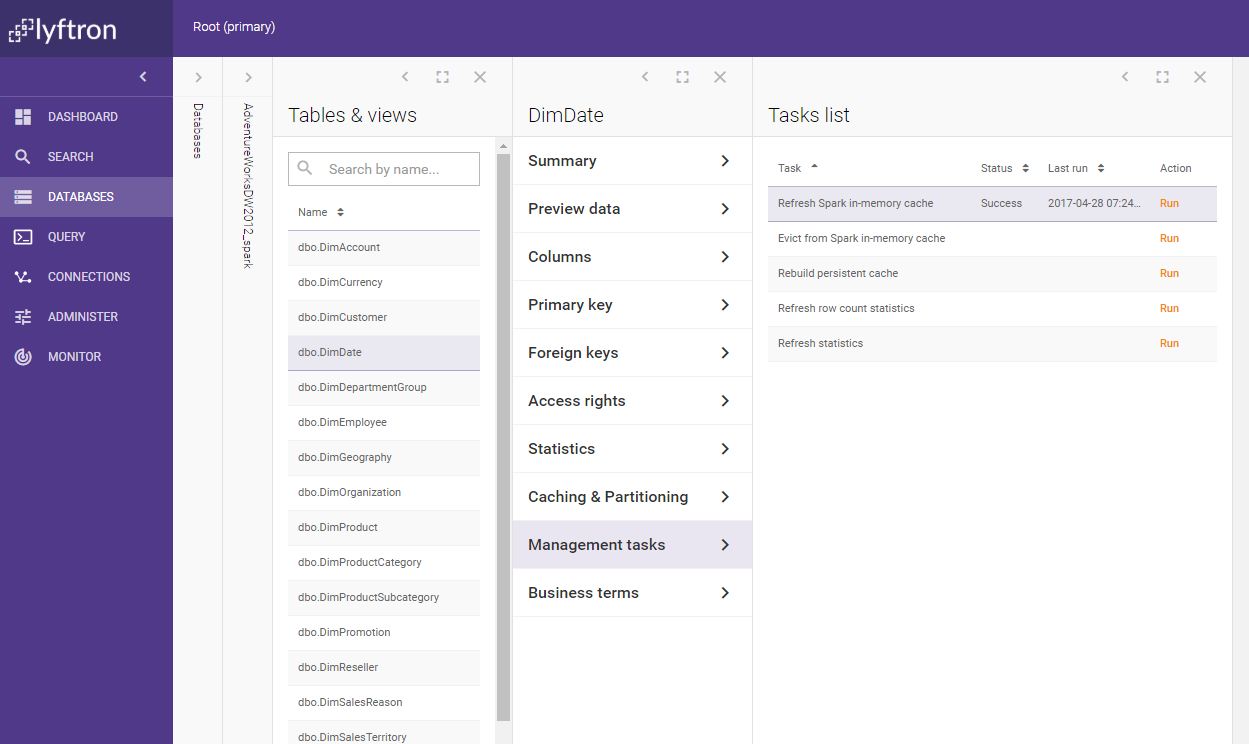
-
You can review caching state on 'Tables & views' tab. Optionally instead of populating cache only once you can set up a job that will refresh cache according to a defined schedule.
-
Instead of clicking 'Run once' as in 6, click 'Define job'.
-
After the job is created, go to Schedules tab.
-
Click 'Add schedule' and select one of the available schedules. The selected schedule will appear on the list.
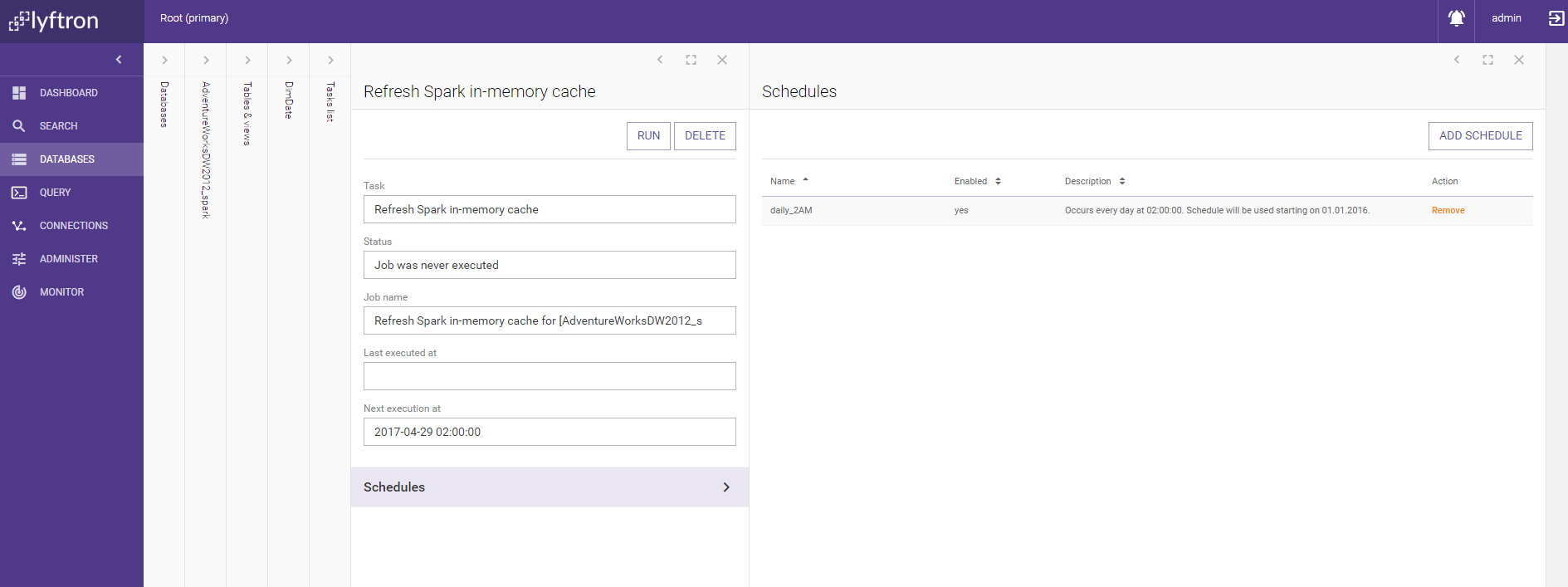
The cache will be automatically refreshed according to the selected schedule.
Caching strategies
Caching is available for views defined in virtual databases which as a back-end use a database engine use one of the supported engines. In-memory cache modes are available only for Apache Spark.
In-memory caching
Data is stored in RAM memory. Access times are better compared to persistent cache mode. On the other hand, when cache hosting process dies, the cache is lost.
Persistent caching - one table
Data is stored in a single table. Table format may differ depending on what data processing system was used as virtual database back-end.
Persistent caching - two rotated tables
Working set of data is stored on disk in a single table, but there is also second 'buffer' table that is used as insert target when the cache is reloaded. When reloading cache, _A and _B tables are both present on disk doubling peek storage needed for caching. On the other hand, cache reload process does not interfere with current queries.
Persistent caching - one table, in-memory
Data is stored both in-memory and on-disk. That mode combines performance with cache persistence, because when cache hosting process is restarted, cached data can be loaded from local storage.
Persistent caching - two rotated tables, in-memory
The combination of in-memory and persistent rotated tables caching. It takes most space, both disk, and RAM, but potentially offers the best performance of in-memory processing while still being persistent and able to reload in the background.
In the case of Spark, table compression may be in effect. Disk and RAM representations can differ.
Index propagation
When the given view has an index defined, the caching mode is set to Persistent, and the underlying provider supports creating indexes by Lyftron, then the index is created and built on the physical data store. This might significantly speed up query execution.
A new index can be defined as well, but propagating it to the underlying provider requires the cache to be recreated.
For more information about indexes see Indexes.
Partitioning
Partitioning is only available for views cached using data processing systems that support it, eg. Apache Spark. Available partitioning modes depend on selected caching mode.
In-memory caching modes
Random repartitioning
Rows will be randomly allocated to all partitions.
Linear column partitioning
Rows will be allocated to partitions based on the selected column value. The number of partitions and min/max values of supported partition keys is configurable.
Column value based
Instead of relying on auto-division of rows, you specify particular values of the partition key for each partition.
Column value ranges based
This mode is extended version of column value based mode. Instead of selecting a single value for each partition, you can choose to use the whole range.
Predicate-based
Most flexible, but also most complicated mode. For each partition, you provide handwritten SQL predicate using views columns. Rows that satisfy predicate will fall into given partition. Note that user is responsible for making sure predicates are valid Spark SQL and are useful predicates for partitioning.
Persistent caching
You select set of columns over which partitioning will be enforced.
Take into account that creating too many partitions (for 10x or 100x times more than available cores) can severely hinder performance. On the other hand, too little partitions (for example 1/10th of available cores) can limit potential parallel processing.