

DataCollection is a systematic approach to collect and measure information from a variety of sources to get a complete and accurate picture of an area of interest. Data collection allows an organization answer relevant questions, evaluate results and make predictions about future trends and probabilities.
Correct and systematic collection of data is essential to maintain the integrity of information for decision-making based on data.There is much talk about Data Driven and other similar concepts,but the right approach is talk about “a culture of data.” We may collect thousands of mobile data applications, visiting websites,loyalty programs, and online surveys to meet clients better but for all, we need a system that allows us to manage all these data securely, applying data governance accurate and compliance with laws regulations.
We know that when we talk about Big Data voluminous amounts of structured, semistructured and unstructured data collected by organizations are described. But, because it takes a lot of time and money to load large data into a traditional relational database for analysis, new approaches to collecting and analyzing all this are emerging. We need to collect and then extract large data for information, raw data with extended metadata aggregating this into a Data Lake. From there, automatic learning and artificial intelligence programs will use sophisticated algorithms to search for repeatable patterns.
The problem arises when there is no kind of control and hierarchy when managing these authentic lake data that sometimes grow steadily without really provide value.
Data Collection vs. Entropy
Logical Data Warehouse intermediate layer
The LDW technology that resides in Lyftrondata allows a new approach and new flexibility when it comes to managing Data Lake it is even possible to dispense with them due to the capacity of an LDW to contact the source directly in real time and without any intermediaries. Why build a data lake if we can develop and model directly using data sources?
Lyftrondata allows a two-way connection. Data flows directly from different sources to different targets. What Lyftrondata does is transform the data sources into an SQL query. Generating views of all data sources and allowing these sources to be combined, joined, mixed and compared. And that’s not all; we’re going to be able to materialize these views within a Data Warehouse on-premise or in the cloud or even within Apache Spark (which may be the most powerful and economical Data Warehouse in the world even if it wasn’t born for this use).
The integration of new data sources is a lengthy and costly process requiring data modeling, ETL custom development work and complete regression testing.
Traditional data models are often biased rigid questions and are unable to accommodate dynamic and ad-hoc data analysis processes. Unstructured data and semistructured cannot be easily integrated. For this reason, the new technology that drive Lyftrondata has born: The Logical Data Warehouse
Tags good stuff for Data Collection
Lyftrondata brings you the possibility to have a data classification and to build a data catalog with tags that enables simple data discovery and avoids repeated collection of the same data. Here are some other features that make Lyftrondata the perfect tool for Data Classification:
Logical data warehouse vs Traditional Data warehouse
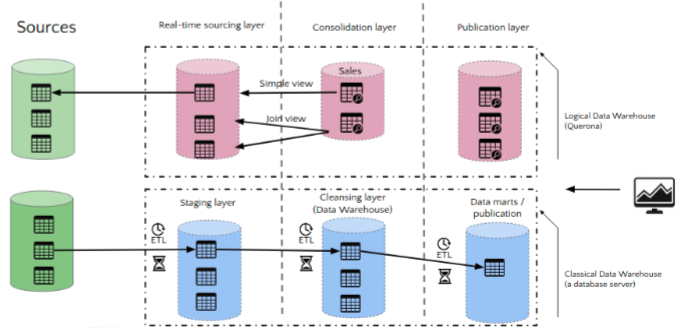
With Lyftrondata, access to the data collected is instantaneous and real-time. LDW technology eliminates the need to copy and move data. It will be possible optionally if we need to correct the data or link it to other sources. In this way, any customer data can be linked to a customer profile in a CRM.
The characteristics of Lyftrondata allow a data unification in a single format that can be used by any tool. Lyftrondata transforms all data into a SQL Query. You’ll be able to have only Data format anytime without ETL process.
For governance, Lyftrondata provides a single and unified security model with access rights, dynamic row-level security, and data masking, and, most importantly, the GDPR-compliance.
Data Collection & Self Service BI
There has been a lot of controversy among industry experts over the ever-increasing trend of a new approach to BI where business information flows without being overly dependent on IT. Recently, Gartner and Barc researchers emphasised this new approach. Lyftrondata is the best tool for a connection between data collection and analysis without “technical” intermediation. No more job for CTO, because the source data is never touched. A Logical Data Warehouse proposes views and does not copy any data, avoiding tedious ETL processes.
Collecting data with Lyftrondata
Data Lake or Logical data warehouse?
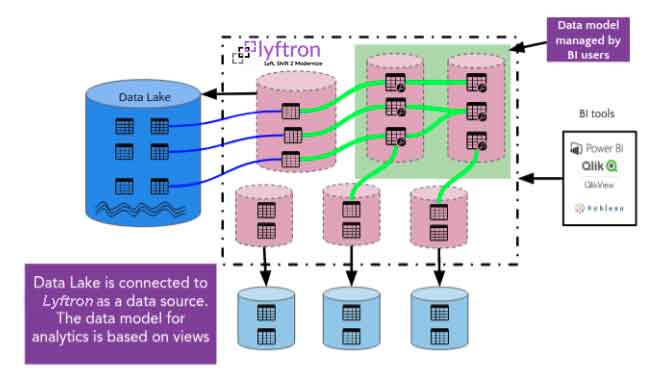
Lyftrondata is a tool that allows you to create a Data Lake in minutes and the data does not need to be updated because Lyftrondata consults it in real time from the source. If you cannot renounce Data Lake due to its use in machine learning environments, we will be able to use Lyftrondata as an anti-corruption layer of the data lake, providing a controlled intake and Data Governance criteria that are less common in traditional Data Lakes.
We see here the characteristics of Lyftrondata LDW:
-
Provide a virtualization with a columnar high performance data engine
-
Emulates engine database most popular and successful on a protocol level (SQL) enterprise-grade, enabling broad adoption and fast without making additional changes to existing tools and infrastructure,
-
Provides a pure virtualization tool data is fully integrated with Microsoft technology (can be a perfect tool to migrate different sources or other databases to Azure)
-
Uses processing engines faster market data such as Apache Spark and others, allowing users easily switch engine and use in parallel.
-
Provides a complete self-service portal and administration based on the web.
-
Provides internal channeling ETL using parallel column processing.
-
Provides a on-premises deployment model, cloud and hybrid.
-
Allows for easy data governance
-
Allows the pseudonymisation fulfilling the GDPR standard
-
Allows for strict control over access to data and solves all safety issues of traditional data lakes.
About Lyftrondata
Lyftrondata provides logical data warehouses, data visualization and data analysis for agile business intelligence. Our commitment to innovation resulted in the development of Lyftrondata™ software platform that makes BI analytics, Cloud & Big Data work easier and faster.
If have problems with multiple data sources, long development cycles BI solutions, inflexibility changes, lack of data in real time or underperformance of reports, Lyftrondata offers a remedy:
- Seamlessly connects more than 100 types of data sources.
- Consolidates data on the fly without an ETL that requires lot time.
- Enables agile development of analytical systems and BI approach.
- Leverages the best Big data SQL engines like Apache Spark 2 to get the best performance.
- Provides a model for any presentation tool or data analysis as Power BI, Excel, Tableau or Qlik.
Lyftrondata integrates perfectly into the cloud architecture of Microsoft Azure giving the possibility to orchestrate data easily and quickly without causing excessive transfer costs and thanks to its pseudo-anonymization of sensitive data helps to contain private cloud investment giving security to dump data into the public cloud without risk








