

Let’s see if we can find another path to success, but this time we will make use of data virtualization capabilities of Lyftrondata.
A Lyftrondata-based approach utilizing data virtualization
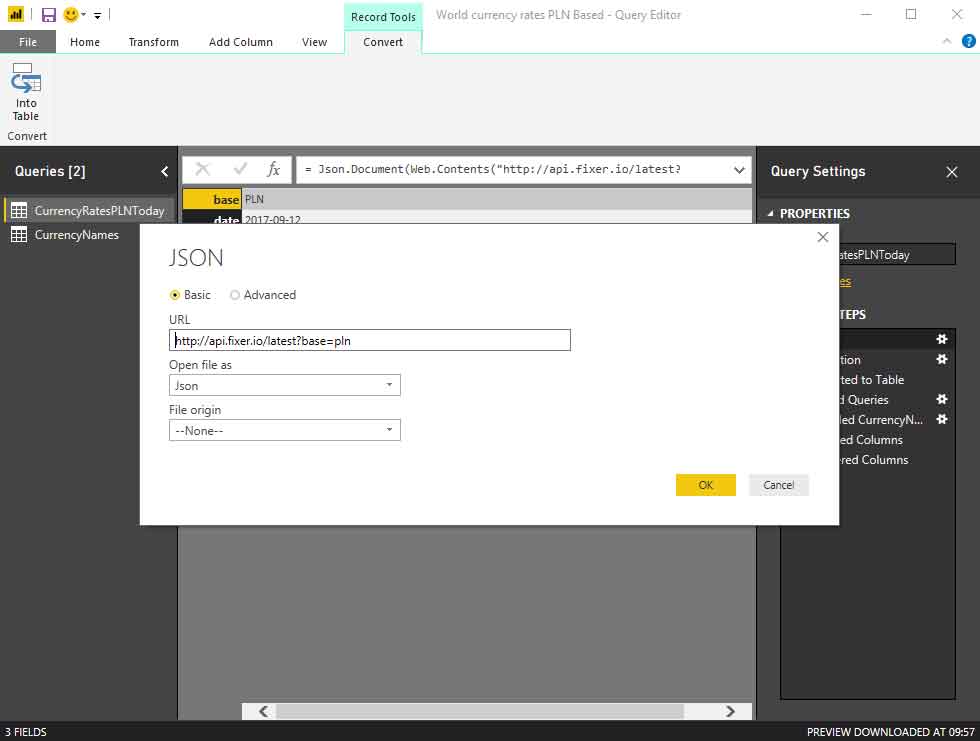
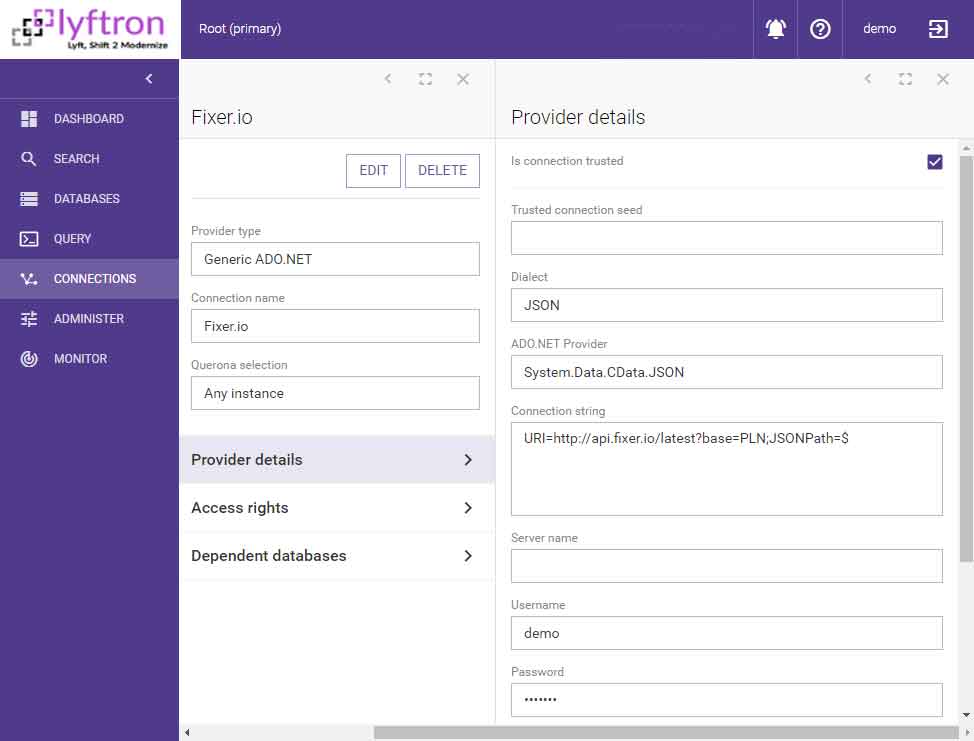
Similar to PowerBI, at the beginning, we need to establish connections to data sources. Let’s connect to Fixer.IO source: we need to select JSON data provider and enter URL and JSON path to the repeating element, which in our case is just “$” (the root):
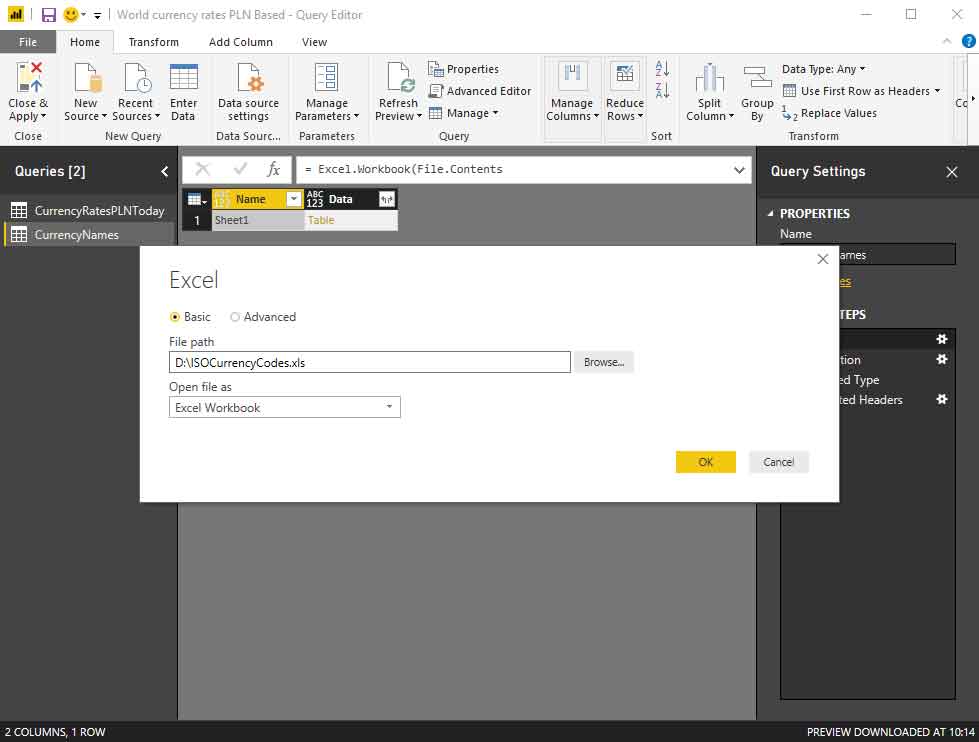
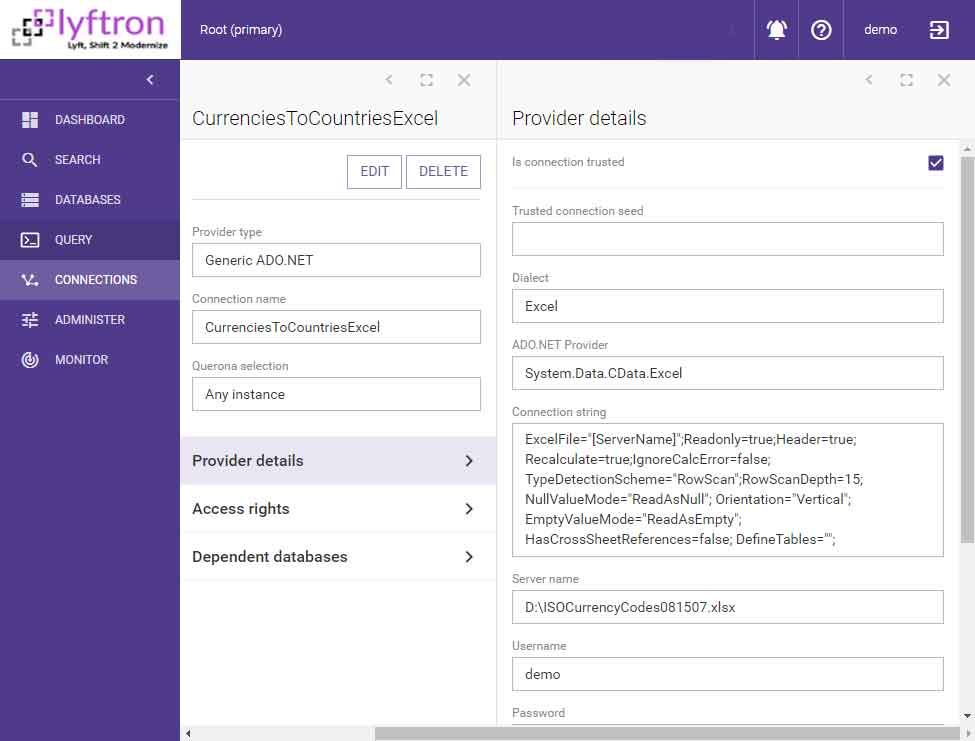
The second source is the Excel worksheet with countries mapped to currency codes. We select an Excel data provider and enter the path to Excel worksheet:
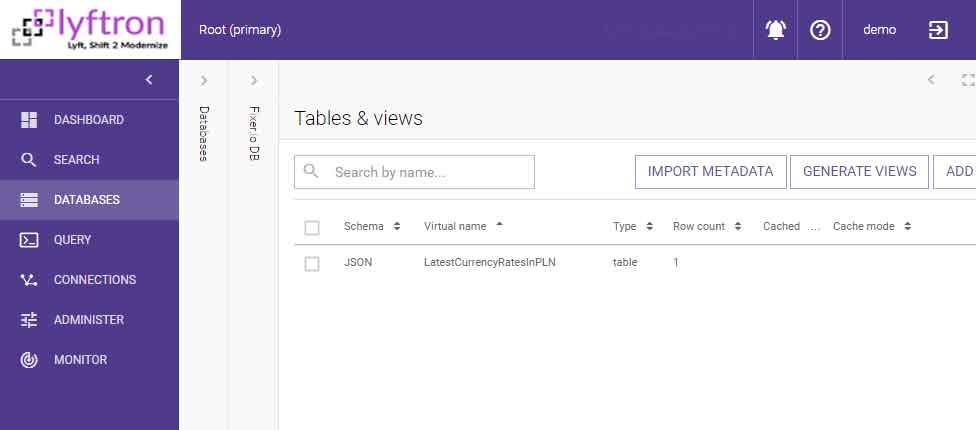
Every data source has its own virtual database registered in Lyftrondata. Here we have [Fixer.io DB]:
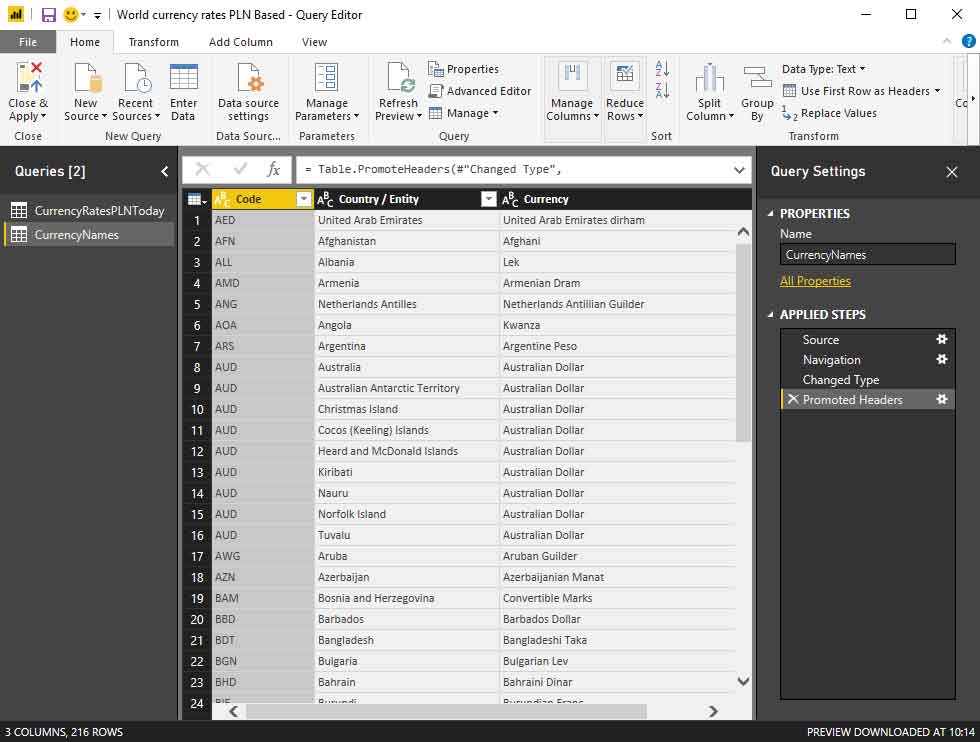
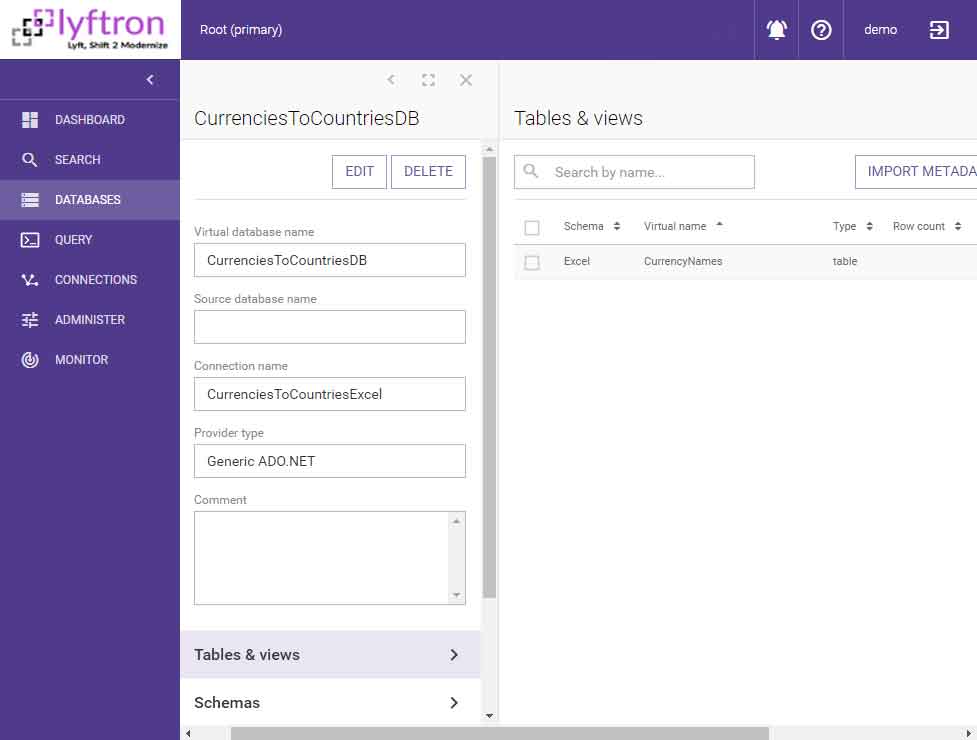
… and [CurrenciesToCountriesDB]:
Since [LatestCurrencyRatesInPLN] is JSON-based and its first representation is just a row, we need to wrap it into a view. So we do manual transpose from:
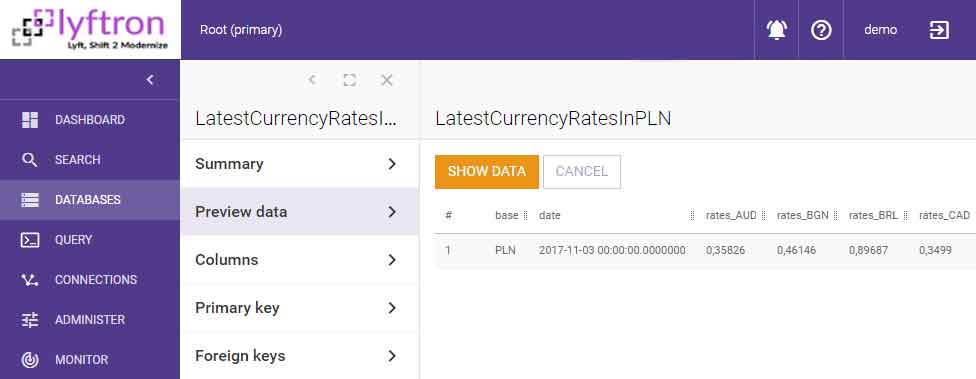
…into:
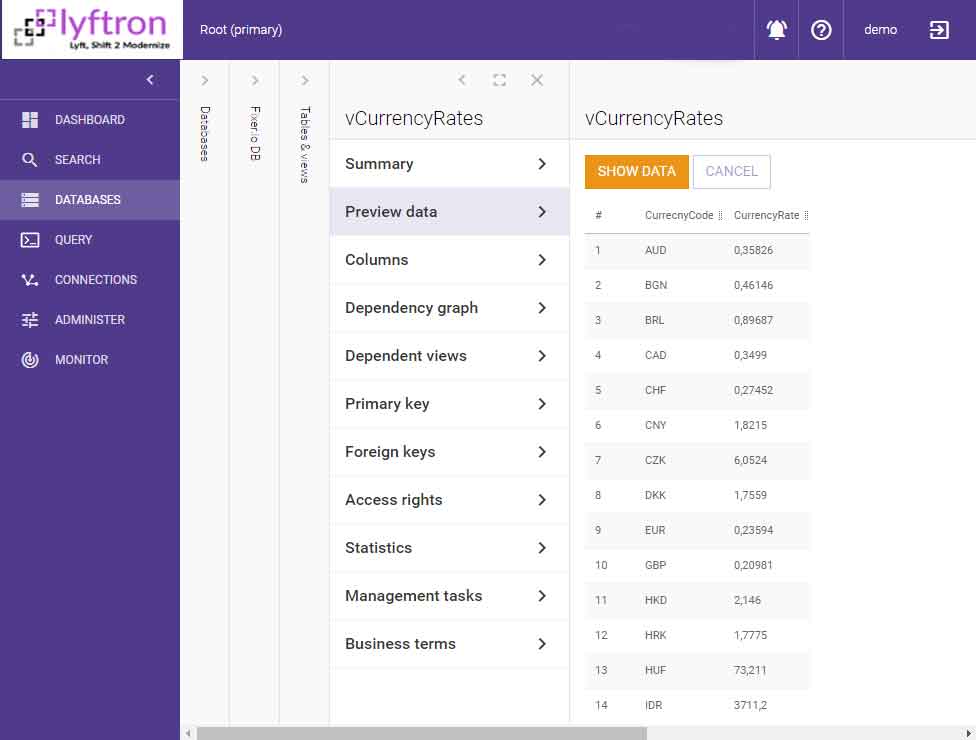
Now it’s time to prepare the final view which will serve as the one and only source for the PowerBI report. The view can be prepared as a joined view:
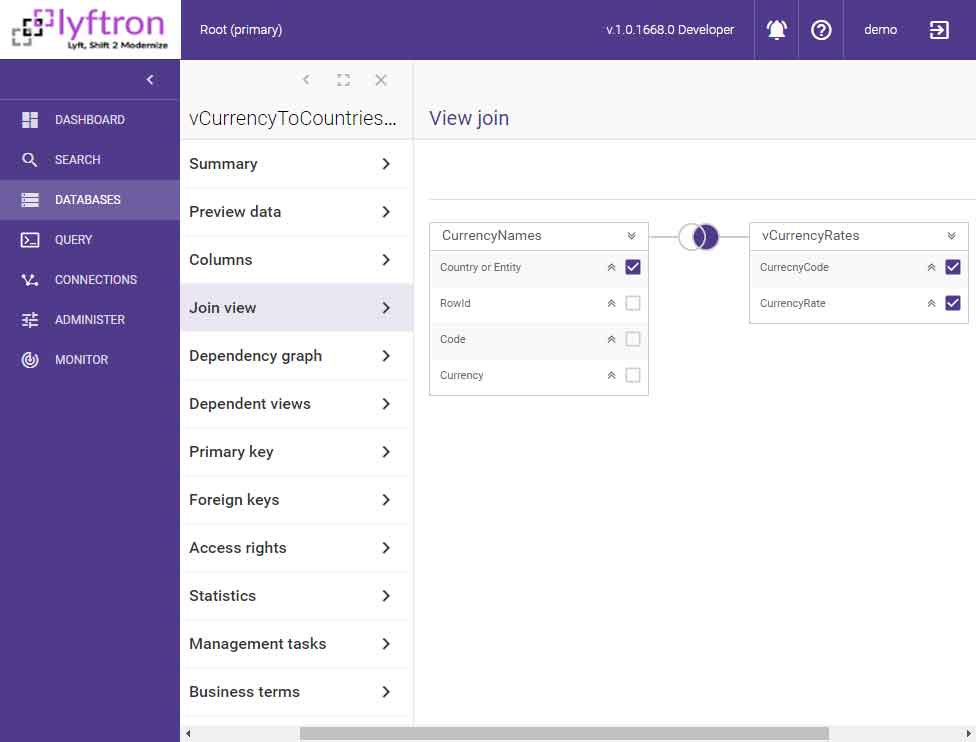
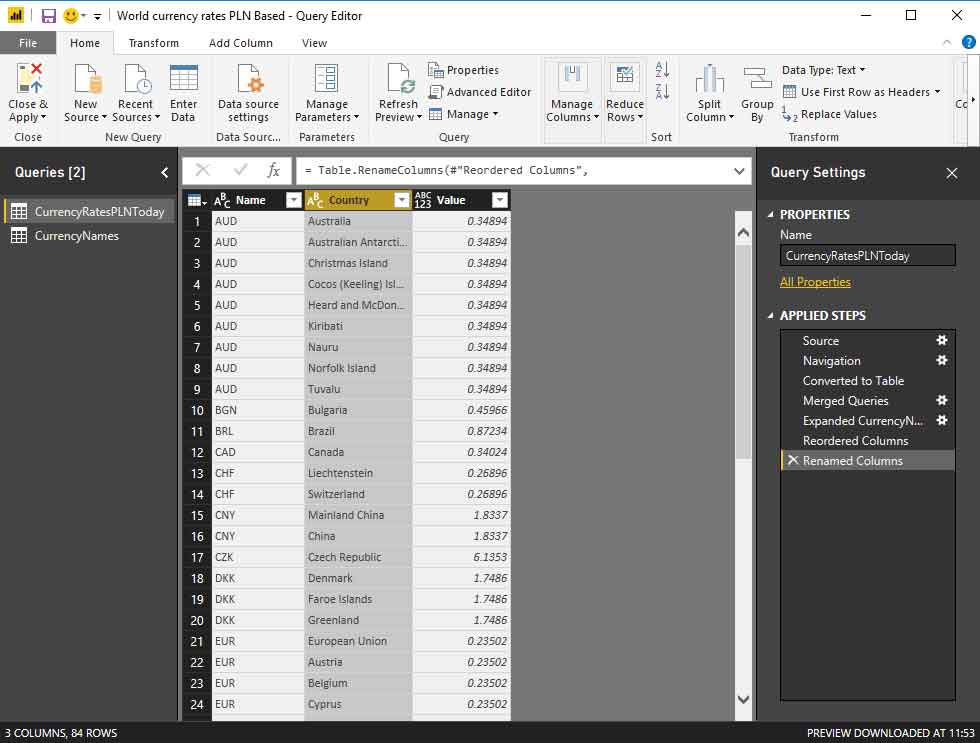
Finally, we have the latest form of data:
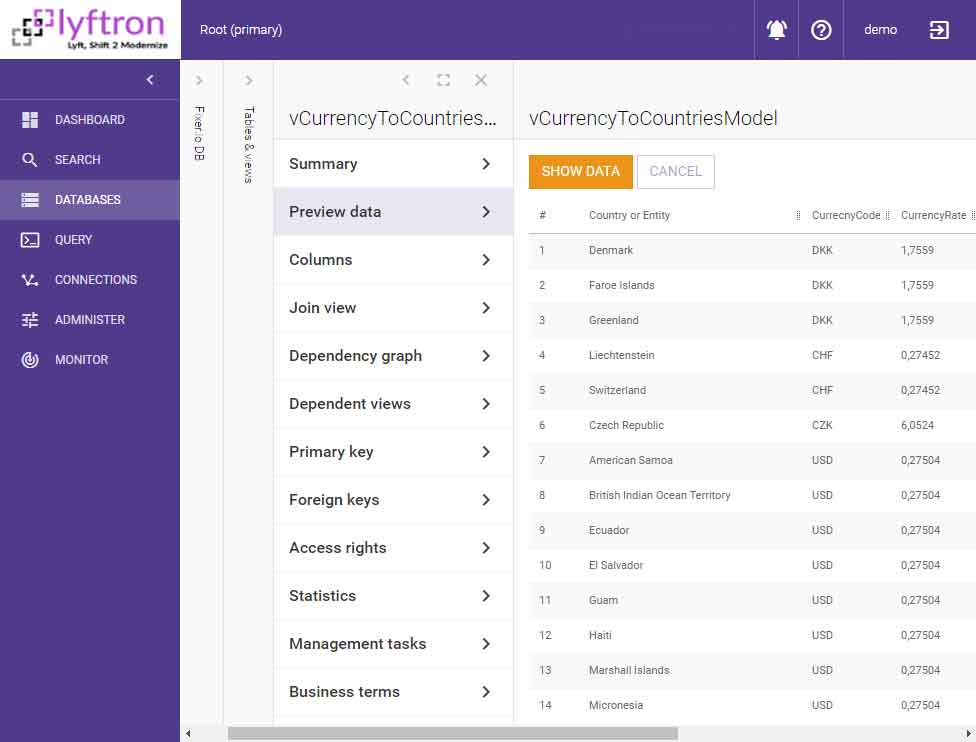
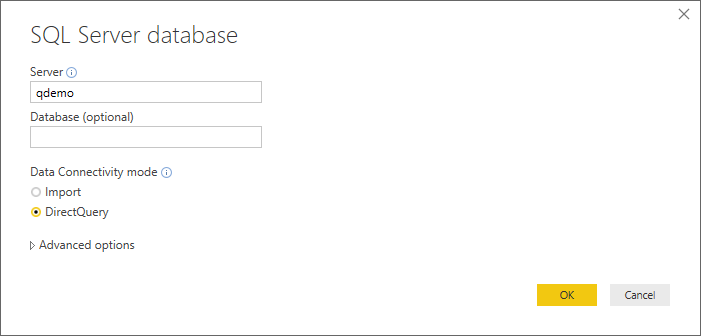
Let’s see how PowerBI can consume the new, integrated data source: 1. Connect to the Lyftrondata instance – please note that DirectQuery mode is enabled and used:
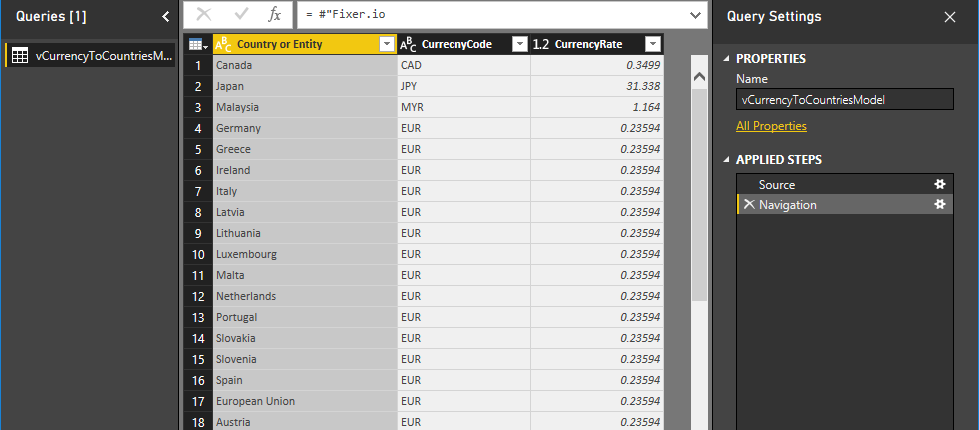
2. Prepare the query:
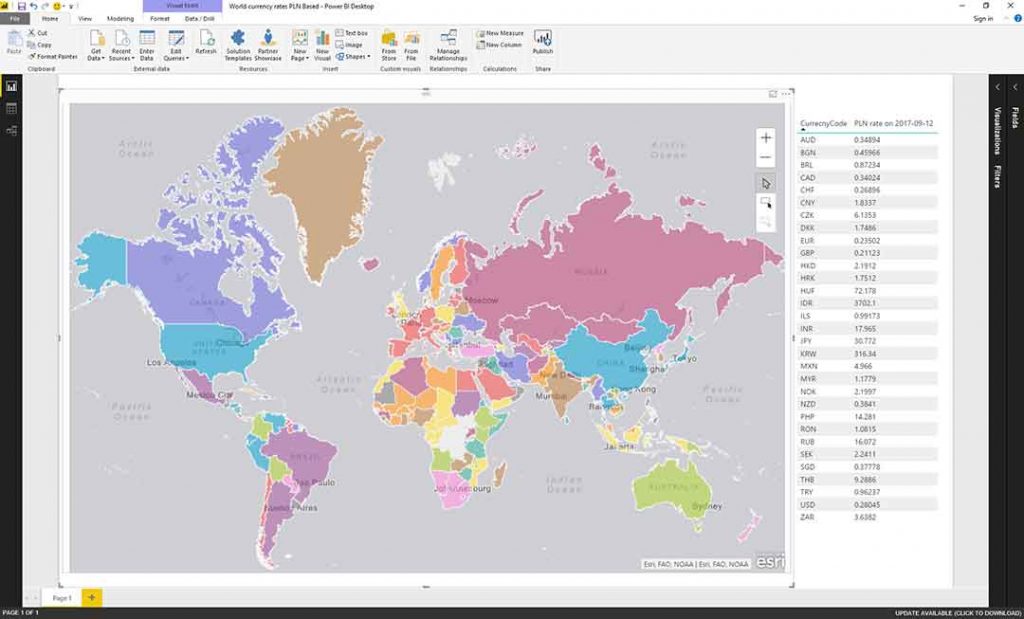
3. Design the report:








