

Increasingly common, innovative business projects have a need to integrate various databases to extract information. Those of us, who were in the industry for long enough, have seen it all. Relational and non-relational databases, CSV or Excel files. Most probably, those sources were not even designed to be used together. Traditionally, some kind of ETL project had to be created. It would load the data into “stage” tables, apply necessary transformations (like data type unification), and finally load the data somewhere. Time of the project would be measured in days or weeks rather than hours. Moreover, qualified staff is required, with knowledge about all source systems and the destination system. Using data virtualization tool like Lyftrondata, time-to-solution can be cut down to hours/minutes for one person. This article will show you step by step how to do it.
Setup
We will describe how to integrate 3 data sources: SQL Server, Oracle and, MongoDB. First, we will import metadata from source systems, then we will show how to join data from those disparate sources using T-SQL and access data using a single data interface.
Metadata Import
To work with external data sources we need to import metadata from those sources. Let’s use Oracle Northwind database and see how to do it in practice using Lyftrondata. Step 1. Go to the Databases panel, click Add Database and fill necessary fields. Select “Oracle” from the list of databases supported by Lyftrondata. We support over 100 data source types.
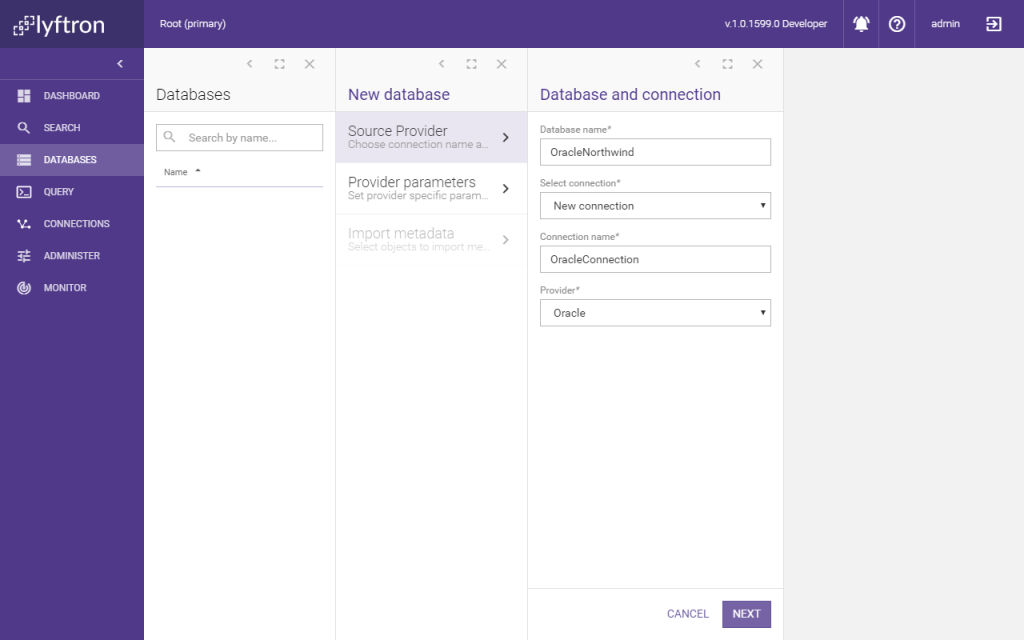
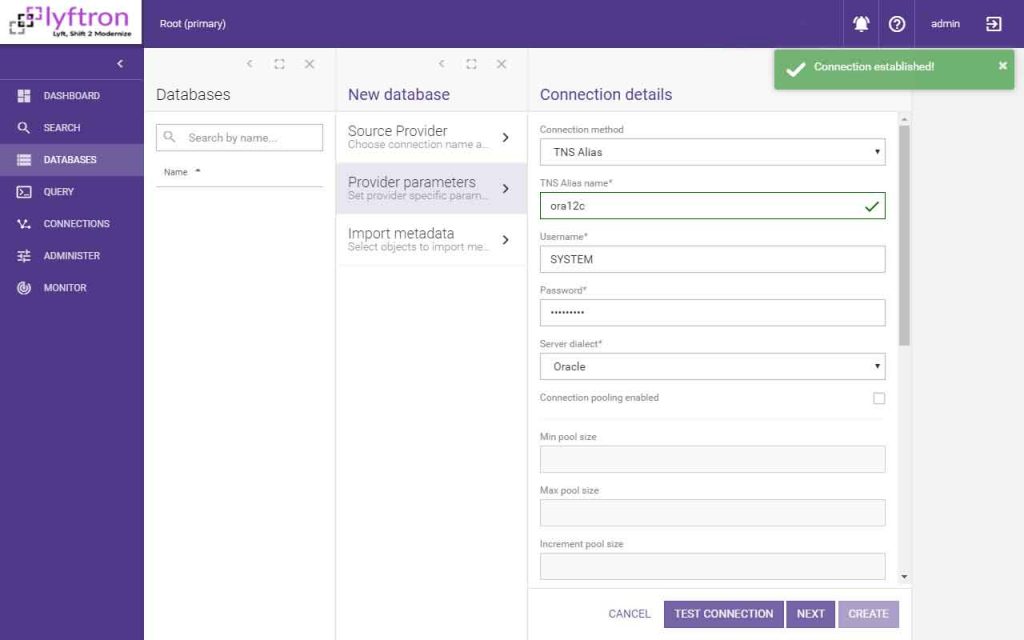
Step 2. Definition of new connection requires us to tell Lyftrondata how to reach the Oracle server. In our case, TNS Alias was provided alongside login and password. To make sure that connection can be established, click “Test Connection” button.
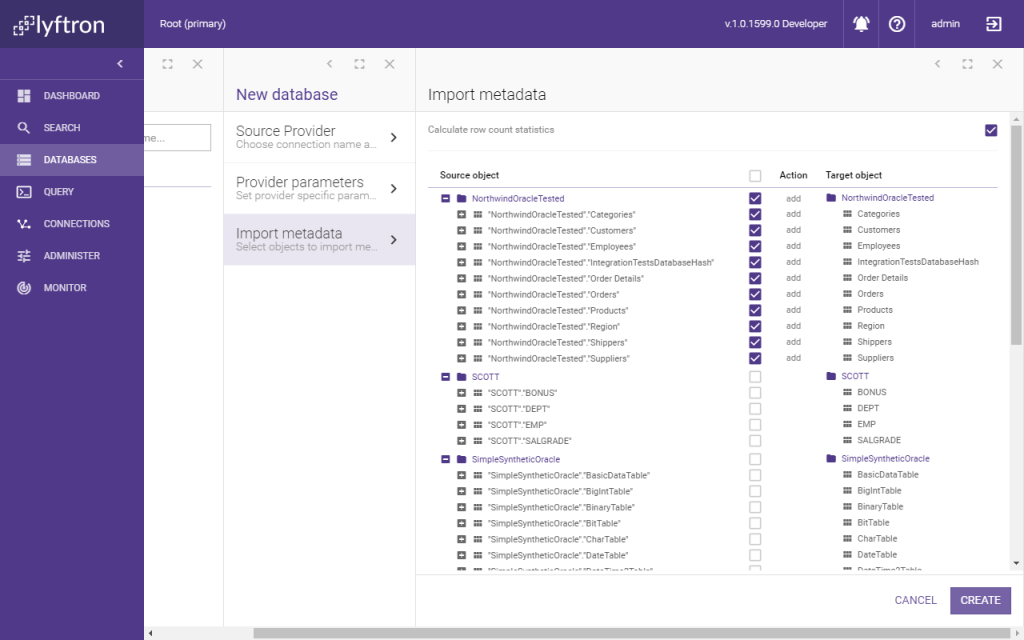
Step 3. Select which tables are we interested in and click the “Create” button. For this example, only the Northwind database will be useful, so that was our selection.
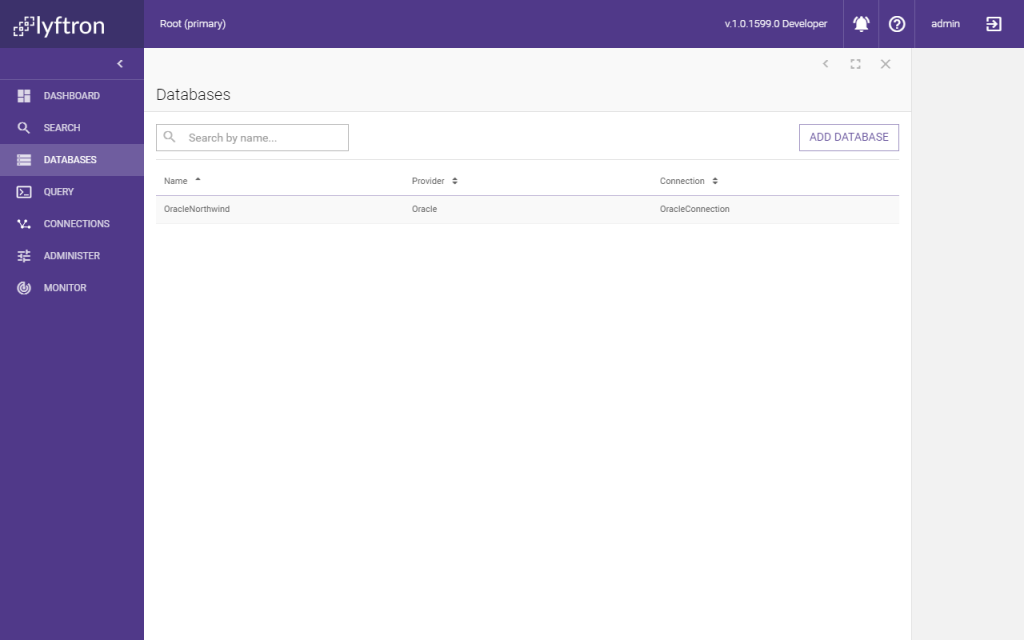
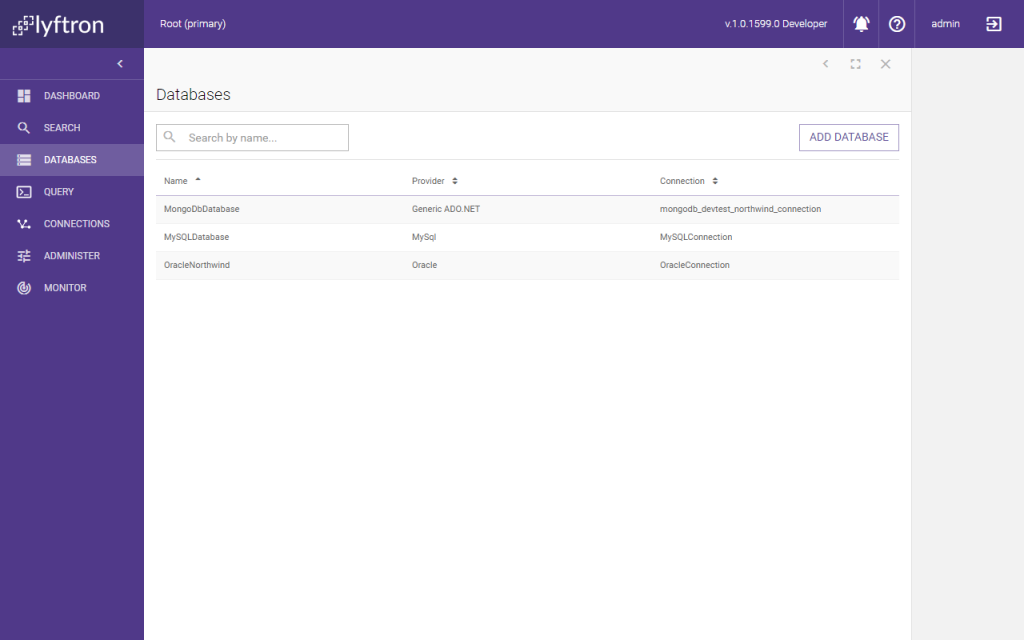
Virtual Database “OracleDatabase” was created and metadata for this Virtual Database was imported from Oracle’s Northwind database into Lyftrondata. Keep in mind that no data was loaded from Oracle.
That is all that was required to connect a data source to Lyftrondata and import metadata. Import metadata process for 2 another sources is very similar, so for the sake of brevity, we will skip it.
Now we can start executing queries against Lyftrondata using standard T-SQL, known from Microsoft SQL Server.
Joining data from all three sources
Now we will show you how easy it is to work with data from those disparate sources. Because Lyftrondata emulates SQL Server protocol (called TDS – tabular data stream), we can connect to it using SQL Server Managment Studio . Our virtual databases are displayed as if they were standard SQL Server databases. Lyftrondata will load data from source systems and join them according to our needs. All the differences of source systems (like different data types, storage models) are accounted for and transparently resolved.
Summary
Data virtualization is a rising technology that dramatically reduces time and cost of integration processes. We have shown how straightforward it is to integrate different data sources, one of which (MongoDb) was not even relational. Hopefully, we convinced you that integrating data from multiple databases does not have to be a lengthy and troublesome process. Instead, using Lyftrondata, you can make it easy, fast and flexible by effectively removing the need for ETL processes.








