

The case
When cloud computing is concerned, we used to think about rapid elasticity, resource pooling or broad network access. All the points are valid but what about security? Is it really safe that data is loaded somewhere off the premises? Are all the legal rules met as well? Lyftrondata supports many nice features, of which one is data encryption.
Data encryption
The untrusted connection is defined in Lyftrondata as a target which the data cannot be pushed to “as-is” but encrypted beforehand. Lyftrondata automatically encrypts the data for you while keeping the data types untouched. String data after encryption is unreadable, but numeric data remains similar to the original data. A few key points for data encryption in Lyftrondata:
- Types are intact – no need to rework a target table schema.
- Data looks pretty real – an ignorant reader might not notice that data is fake because dates keep the age, and numbers keep precision and scale.
- The consistency of encrypted values based on equal originals – you can still query the table because predicates will work (linkability).
- Encrypted content can be decrypted manually using built-in functions.
In the example below, we will create a cache of data in the cloud database. The goal is to store and process view data in the cloud while keeping the cached data encrypted in the target database.
The Solution
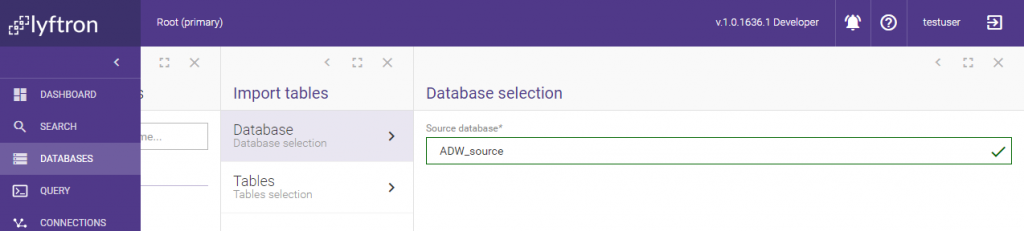
Let’s create a virtual database called ADW_source and import its metadata (you can read about it in the previous post: “How to integrate disparate data sources in 10 minutes”). First, we create the virtual database itself:
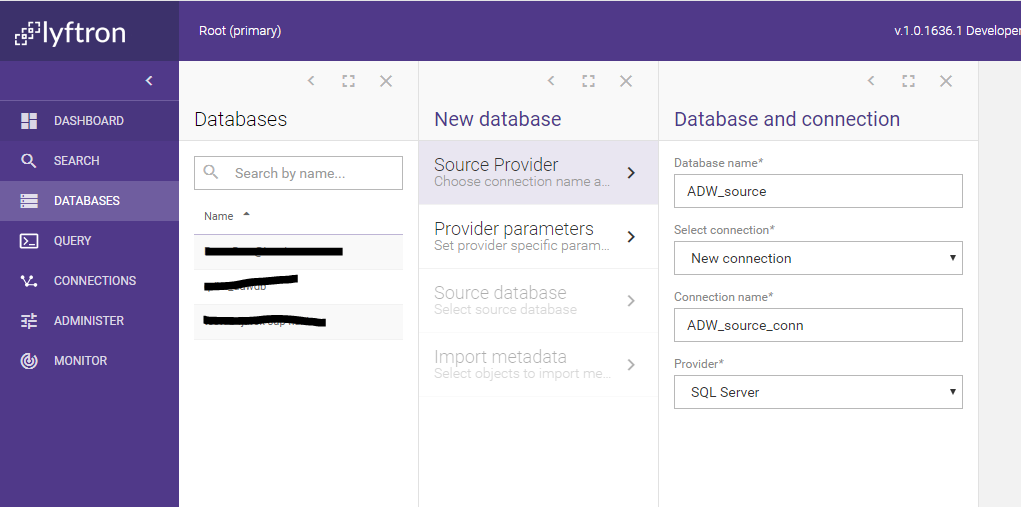
Our new target connection is on the local network, thus let’s treat it as trusted. Data processed using trusted connection is not going to be encrypted.
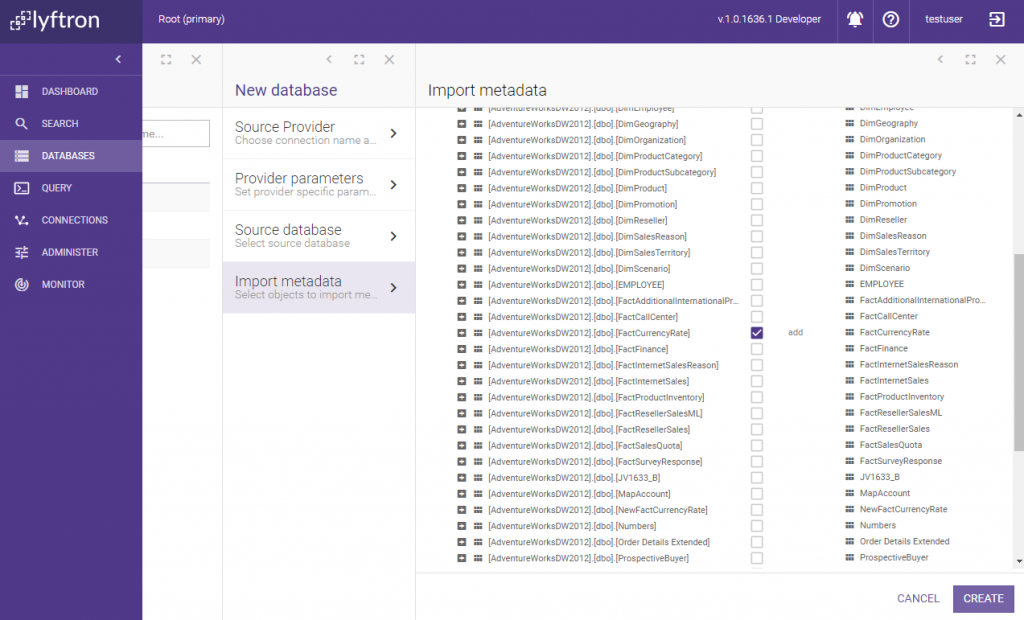
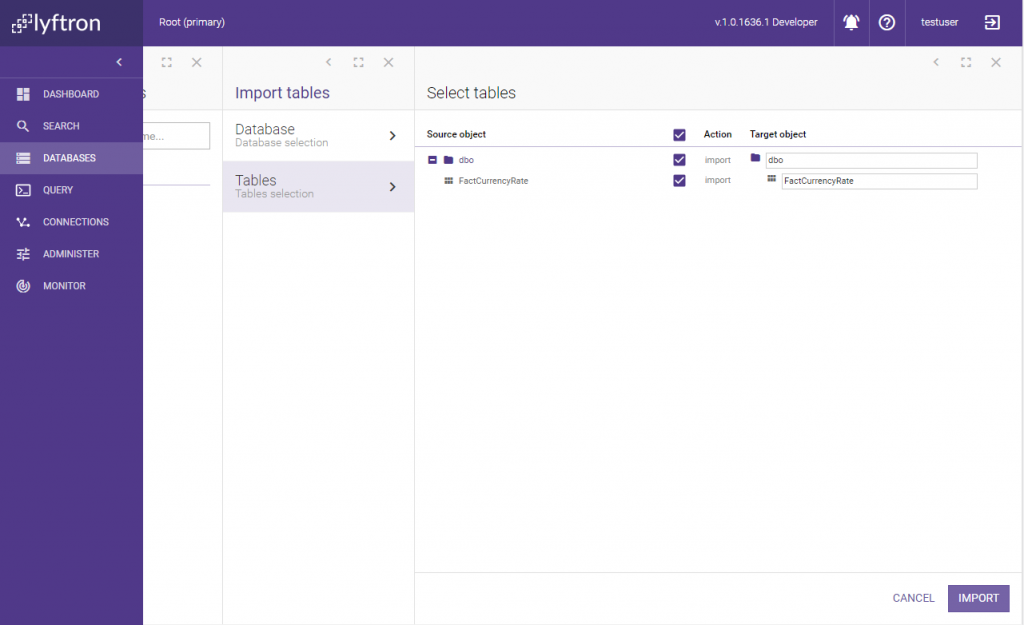
We need only one table metadata to be imported. We use FactCurrencyRate in our case:
Our virtual database was created:
We need only one table metadata to be imported. We use FactCurrencyRate in our case:
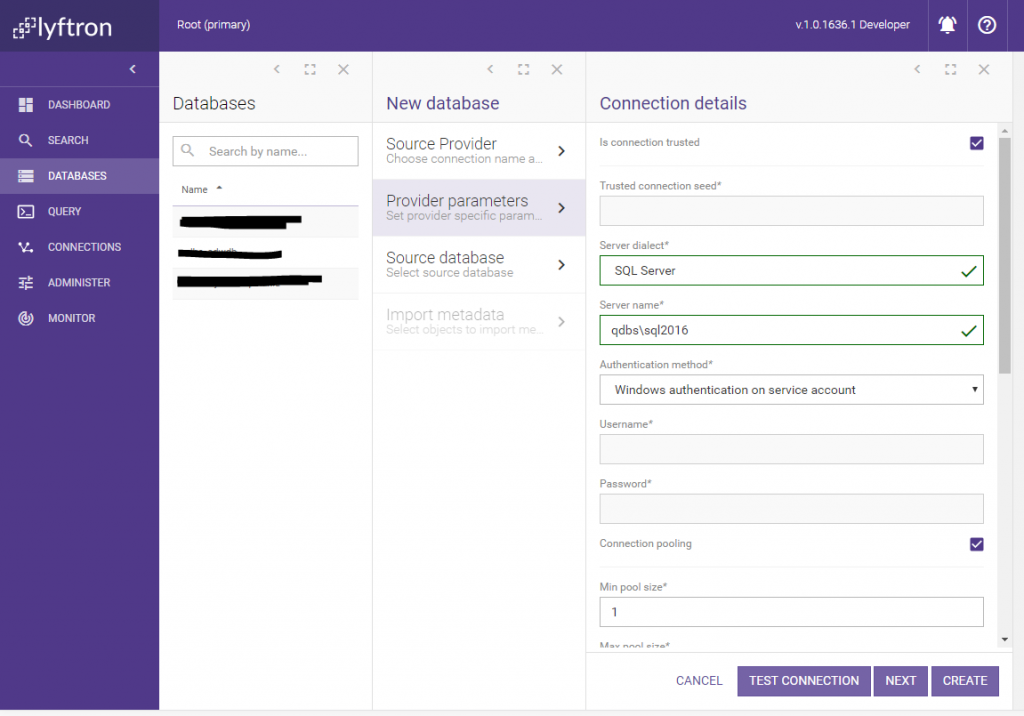
This time we set the connection is untrusted, to inform Lyftrondata that it needs to take special care of data marked as sensitive. Untrusted connection requires a seed value which forms a base encryption parameter used for this connection (and all databases base on the connection). The seed value requires an integer value within the range defined as follows: -2147483648 — 2147483647. Our connection requires also BULK INSERT batch size parameter which we will discuss later, so now let’s leave it as it is by default.
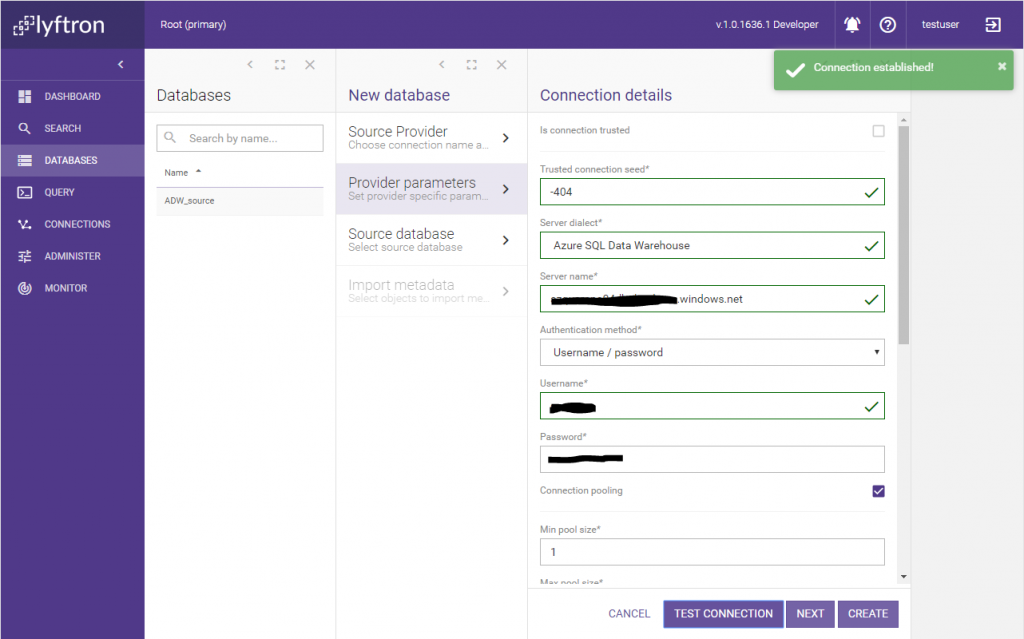
Next step is to add a virtual database that we will use for data caching and processing. We will use Azure SQL Data Warehouse database hosted in Microsoft Azure cloud. The new database name will be AzureDWCache_source.
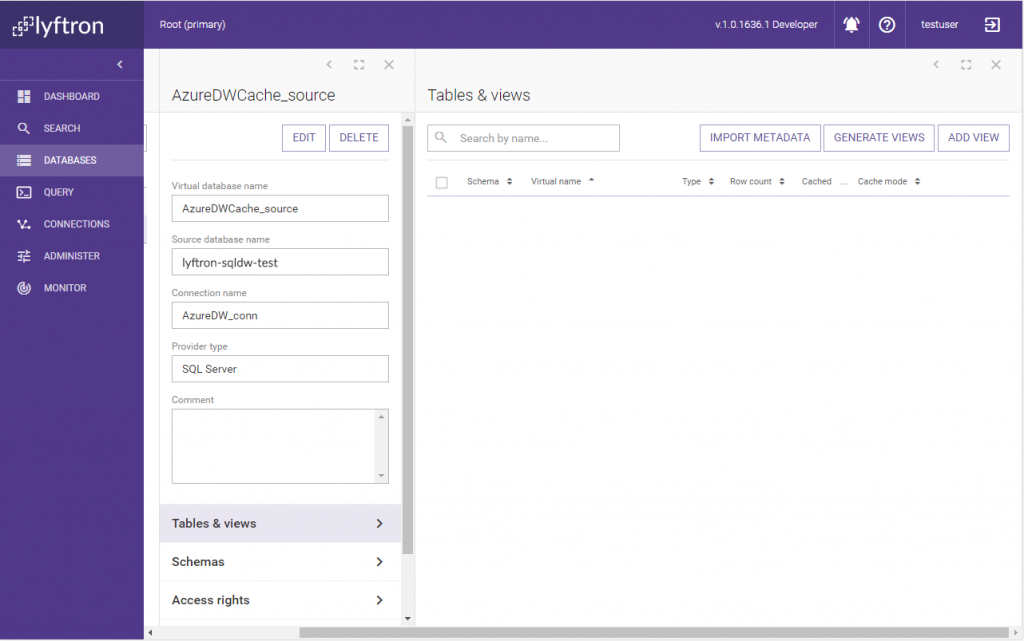
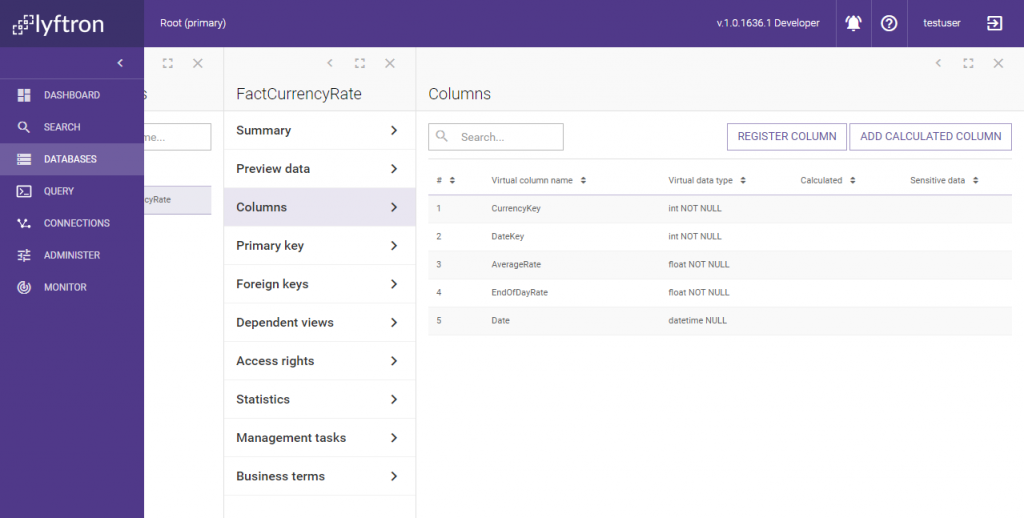
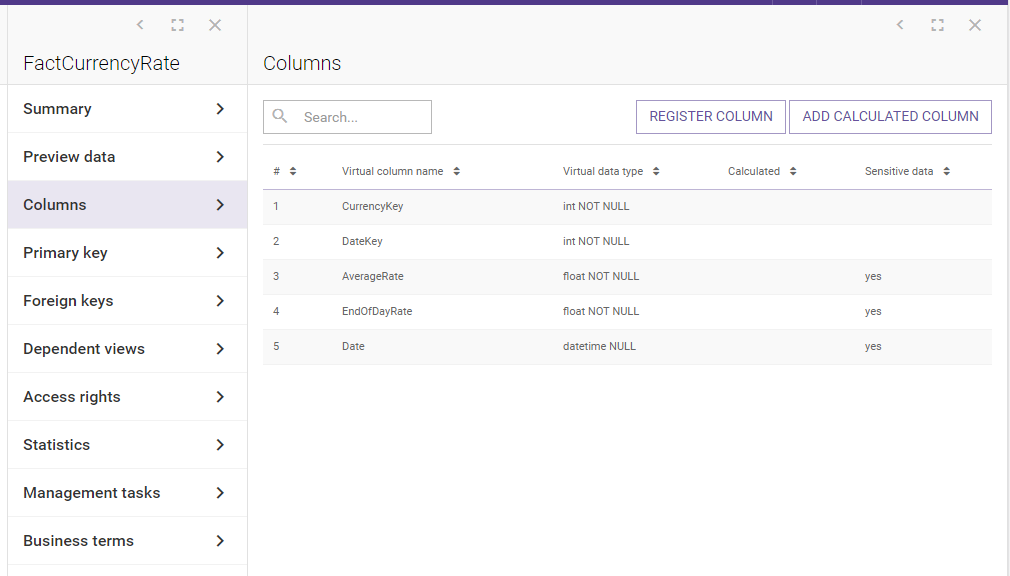
Now, before table FactCurrencyRate is cached in the Azure cloud database, we need to mark a few columns as sensitive. Let’s go to the source table column list:
We want to mark some columns as containing sensitive data. We set column AverageRate property “Contains sensitive data” to true and save our changes:
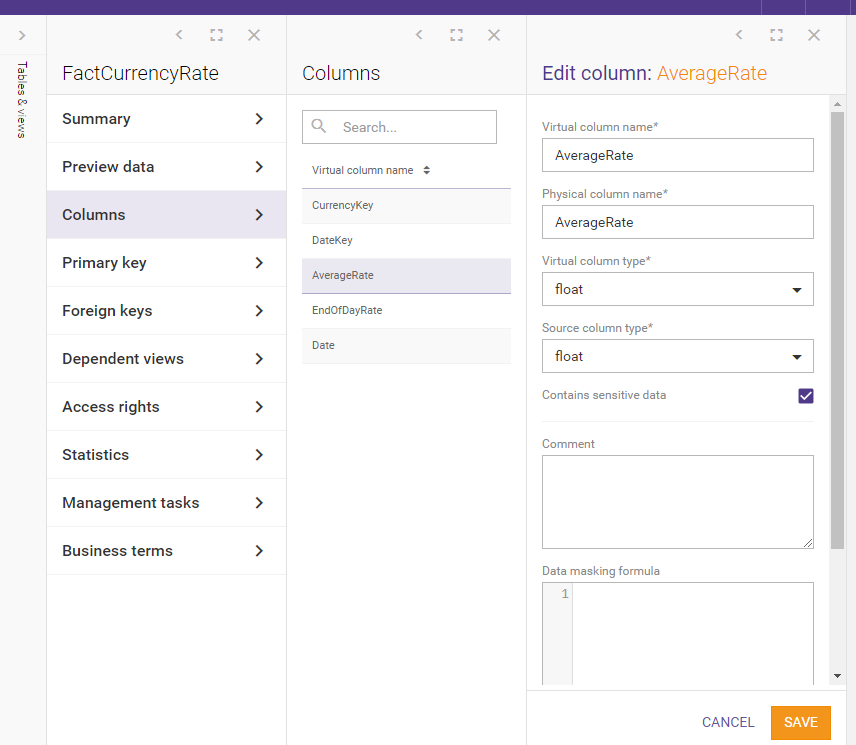
We do the same for EndOfDateRate and Date columns. All three columns which hold data marked as sensitive are as follows:
To encrypt cached data on AzureDW we need to create a view in AzureDWCache_source DB. To do so we go to the database properties, open Tables & views and click Generate views menu item. We select ADW_source as the “Source database”. We’re going to import one table:
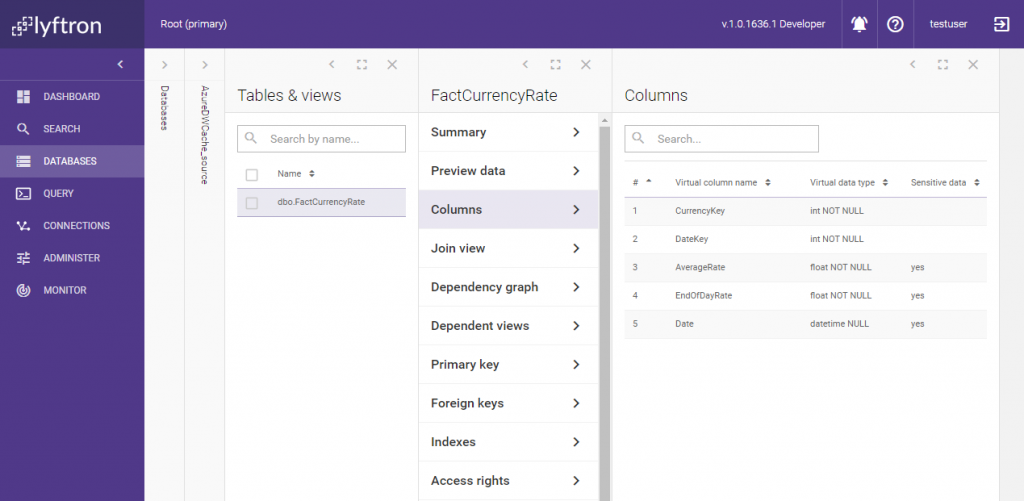
Now, AzureDWCache_source contains the desired view. What about the column sensitivity information? We have marked columns in the source virtual database as sensitive, so this information should propagate further and affect the sensitivity setting of the columns in the view, right? Let’s check this out:
To make data cacheable we need to set a proper caching of the view. We select caching strategy to use one physical table:
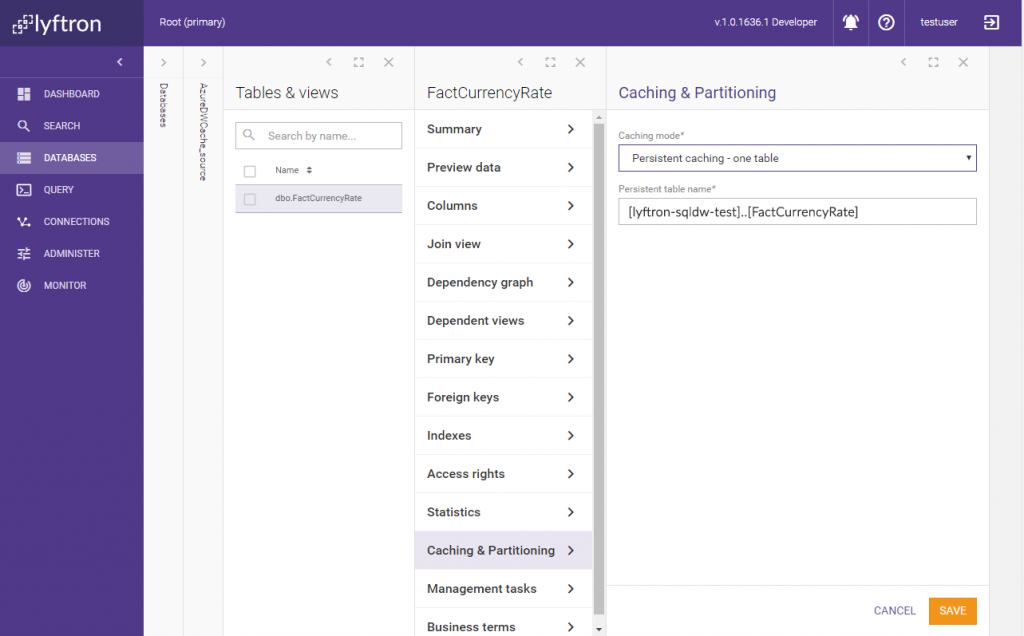
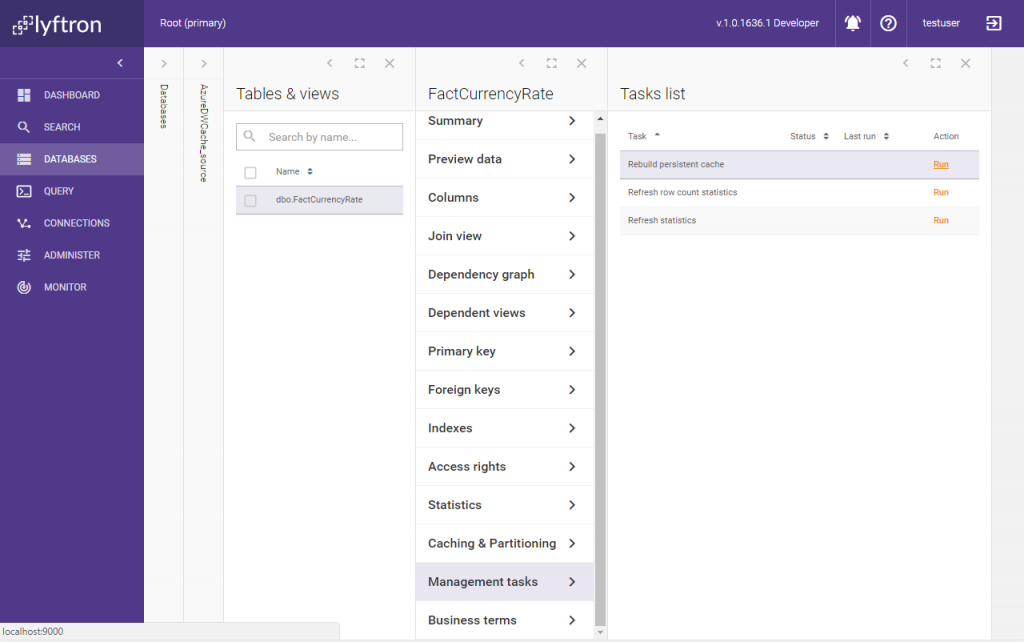
When the task is finished, we check Caching & Partitioning for details:
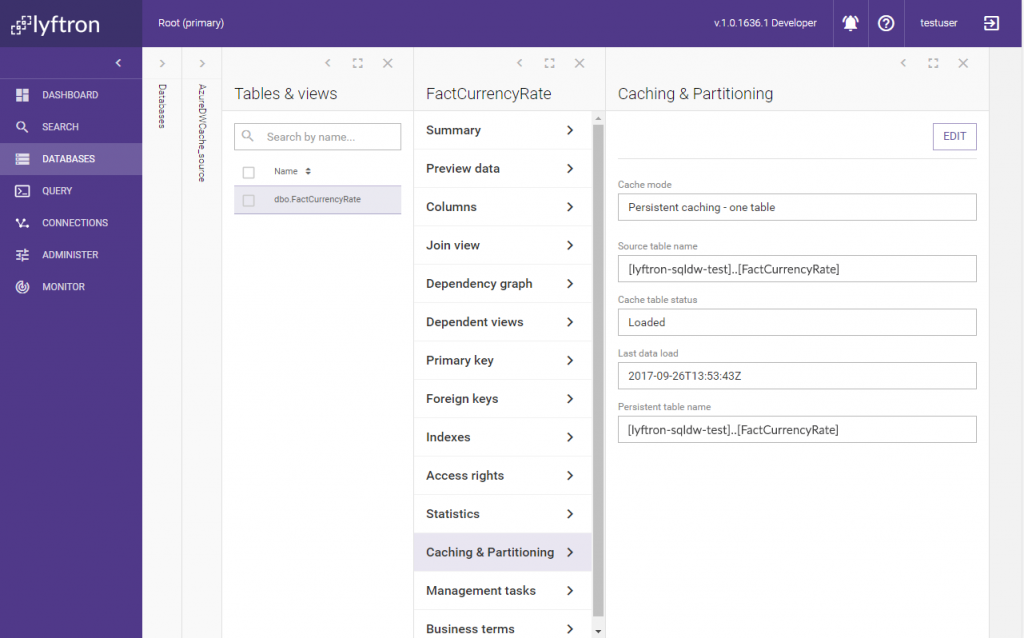
We see that the cache was created and loaded. Now we know that the data is cached in the SQL Data Warehouse database in Azure. What about the cache contents? Let’s check our cloud database and connect to it directly using SQL Server Management Studio:
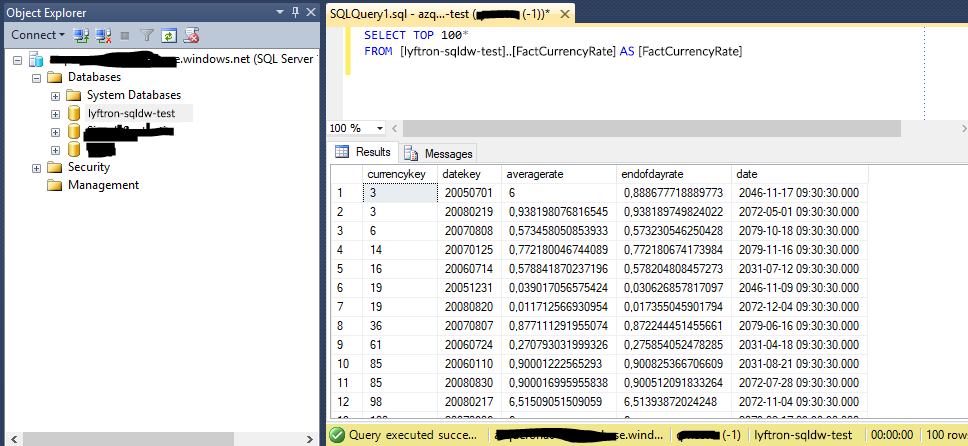
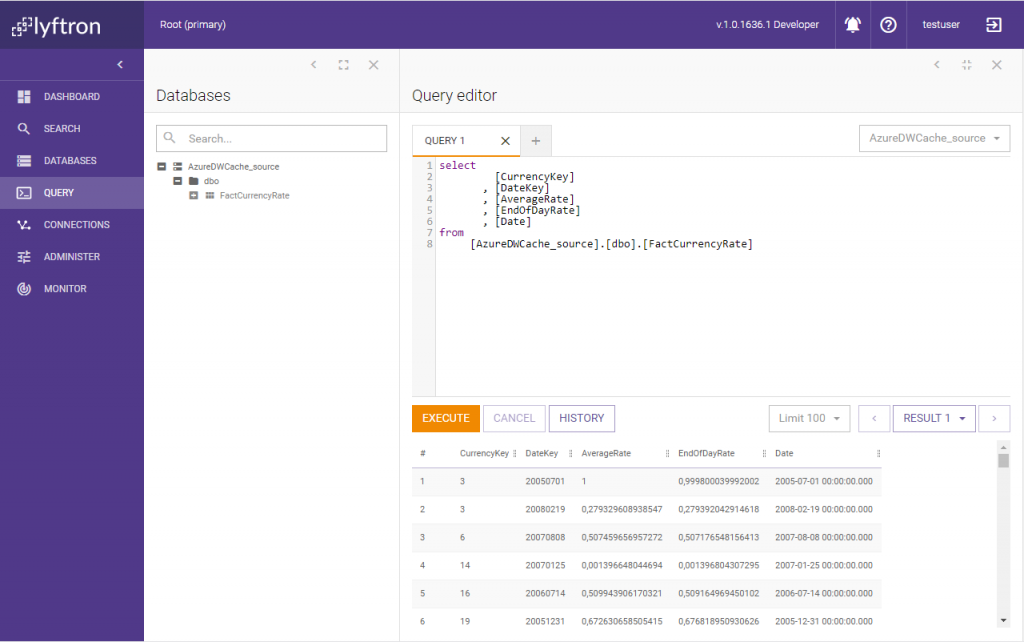
As you can see there is a table created named FactCurrencyRate that holds our cached data. But the data inside is different than original one coming from ADW_source database – columns AverageRate, EndOfDayRate and Date contain data which looks pretty similar to the original, but actually, only the format is the same. How does Lyftrondata handle querying such a cached view? Let’s go back to Lyftrondata and check by executing the query below: select [CurrencyKey], [DateKey], [AverageRate], [EndOfDayRate], [Date] from [AzureDWCache_source].[dbo].[FactCurrencyRate] using Query editor and see the data.
Data displayed is the same as the original, as no data encryption was performed…
NOTE: There is also another way, more advanced, to check if the query was actually performed against the new table. This feature is called Execution plan cache and for sure will make you in love with Lyftrondata even more, so… stay tuned to Lyftrondata!
OK, you might think that Lyftrondata does not reverse the data encryption and gets the data directly from the source database rather than the cache in the cloud. Let’s kick the source database out of the system and delete ADW_source database. Now the only one database left is the one based on Azure SQL Data Warehouse:
Let’s do the final check and query the cached view again:
Wow, it still works! Data looks familiar… In this article we have shown:
- How to connect Lyftrondata to on-premise database and mark selected columns as containing sensitive information
- How to connect Lyftrondata to SQL Data Warehouse database in the Azure cloud and mark it as untrusted in Lyftrondata
- How to cache (materialize) a view containing sensitive information in an “untrusted” database
- How to verify that encryption of sensitive data actually took place and data cached (materialized) in the untrusted database was encrypted automatically by Lyftrondata
- Cached, encrypted data taken from the untrusted database, is presented by Lyftrondata to the user in it’s original, decrypted form.








