Overview of Modern Data Hub
Modern Data Hub technology is based on the execution of distributed data management processing (primarily for queries) against multiple data sources, federation of query results into virtual views, and consumption of these views by applications, query/reporting tools or other infrastructure components. It can be used to create virtualized and integrated views of data in-memory (rather than executing data movement and physically storing integrated views in a target data structure), and provides a layer of abstraction above the physical implementation of data. (Gartner)
Modern Data Hub represents an agile approach to data integration. It provides to data consumer an abstraction layer that hides most of the technical aspects of how and where data is stored, processed and how it's accessed. It allows accessing resources without delving into details like:
- where data is stored,
- what technology or platform is used to store data,
- what technologies are used to process and store data,
- what interfaces are needed to access data.
Modern Data Hub does not eliminate classical approach. It can coexist with legacy systems and can be immediately used to augment and modernize existing BI solutions.
Objectives of Modern Data Hub
Objectives of DV are as follows:
- add flexibility and speed to traditional data warehouses and data marts
- make current data available quickly 'where it lives', which can be useful when:
- data is too large to practically move
- data movement window is small
- data can not be legally moved out of a geographic region
- enable user access to various data platforms
- reduce data latency and enable real-time analytics
- facilitate a polyglot persistence strategy (after M. Fowler), which simply means to use the best storage and processing solution to the problem at hand
Benefits
With Modern Data Hub, organizations benefit in the following important ways:
- productivity boost, thanks to relatively easy to use and straightforward Concept Modern Data Hub relies on.
- better time-to-solution and time-to-insights. Projects that utilize Modern Data Hub take less time and resources, therefore business results are delivered faster and cheaper.
- technology optimization. Optimal usage of infrastructure, fewer data storage, less dependency on hardware, result in smaller costs of ownership.
- data democratization and self-service for business users. Users are less dependent on IT when empowered with easy to use, instant access to all the data they need to gain more business insights.
Usage patterns by role
| User type | Purpose |
|---|---|
| Business Leaders | Modern Data Hub helps to drive business advantage from organization's data. |
| Information Consumers | From spreadsheet user to data scientist, Modern Data Hub provides instant access to all the data users need, the way they want it. |
| CIOs and IT Leaders | Modern Data Hub allows for agile integration approach that lets organizations respond faster to ever changing analytics and BI needs and do it for less. |
| CTOs and Architects | Modern Data Hub adds data integration flexibility so organizations can successfully evolve their data management strategy and architecture. |
| Integration Developers | Easy to learn and highly productive to use, Modern Data Hub lets deliver more business value faster and is easier to maintain. |
Modern Data Hub with Lyftron
Lyftron provides a common abstraction over any data source type, shielding users from its complexity and back-end technologies it operates on. It relies on views that allow users to integrate data on the fly. Views provide instant access to the data business requires. Emulation of one of the most popular database server in the world allows for quick integration with existing infrastructure, reporting solutions, cloud and AI.
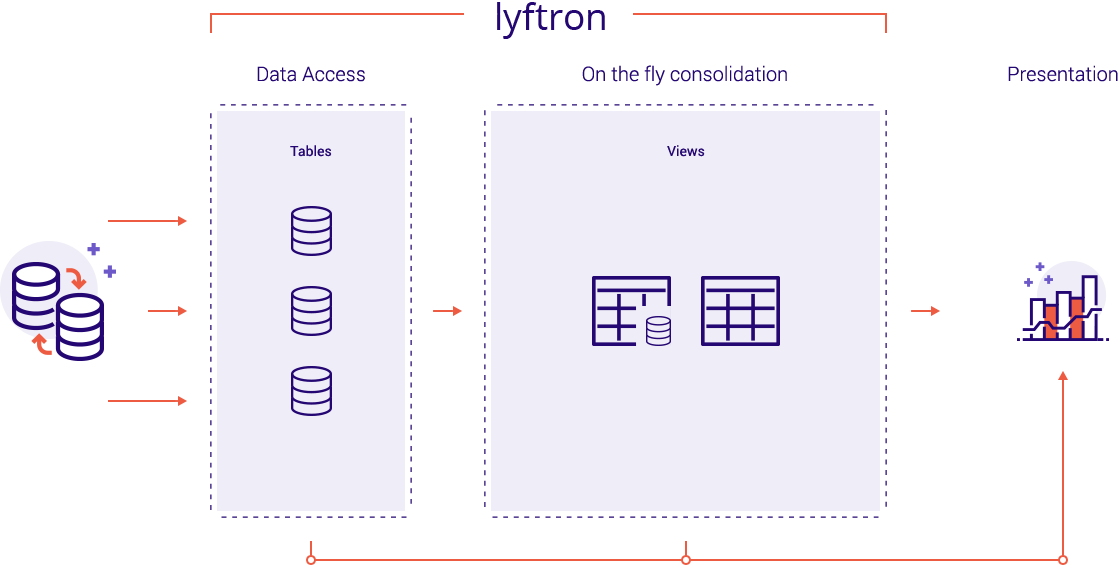
Lyftron seamlessly connects any data source with any data consumer like Tableau, Power BI, Microsoft Excel and others. It does not create another copy of the data, unless acceleration of processing is required or other requirements force data movement. Just write standard SQL query (or a view) and let Lyftron consolidate data on the fly, use one of execution engines and accelerate processing no matter what kind and how many sources you have.
Lyftron simplifies architecture comparing to classical data warehouses:
- Helps to eliminate time-consuming ETL and enables data consolidation on the fly.
- Lets to build your own universal data model and share it among reporting tools.
- The data model is separated from execution engine and BI front-end.
If performance of on-the-fly consolidation is not acceptable, view data can be cached using any of the supported database platforms:
- Apache Spark, built-in, created for purpose of Big Data analytics, managed and distributed with Lyftron default installation
- Any external Apache Spark instance with or without Hadoop, on-premise or as SaaS (Azure, Amazon, others)
- Microsoft SQL Data Warehouse (Azure)
- Microsoft SQL Server (on-premise or Azure)
- Amazon Redshift (Amazon)
- SAP Hana (on-premise or cloud)
The above platforms can be used simultaneously and complement each other, allowing users to build an optimal solution to the case at hand. For example, heavy data processing can be done using Apache Spark, while ad-hoc reporting queries can utilize SQL Server at the same time.
Lyftron vs Database server
The following table presents mapping of features between database server and Lyftron:
| Feature or responsibility | Database server | Lyftron |
|---|---|---|
| data dictionary management | Yes | Yes |
| data storage management | Yes | external, eg. Apache Spark |
| data transformation and presentation | Yes | Yes |
| security management | Yes | Yes |
| multi-user access control | Yes | Yes |
| backup and recovery management | Yes | external |
| data integrity management | Yes | Yes, not enforced |
| database access languages and API | Yes | Yes |
| database communication interfaces | Yes | Yes |
| transaction management | Yes | per SQL Engine involved |