Preface
This manual provides an architectural and conceptual overview of Lyftron, which is a self-service Data Foundation Platform for BI and Analytics. It describes how the Lyftron platform functions, and it lays a conceptual foundation for much of the practical information contained in other manuals. Information in this manual applies to the Lyftron platform running on all supported operating systems.
Introduction
The primary reason that companies implement Business Intelligence (BI) solutions is to support and improve their decision-making process. Changing world puts pressure on companies to react and make decisions faster. Time to decide is shrinking and companies find it harder to make timely decisions. Organizations need to be agile and embrace change quickly by adopting their culture, existing IT systems and reporting. New valuable, external data sources emerge frequently. Cloud usage is growing due to the utilization of SaaS platforms, putting more pressure on companies IT and operations. New technologies like analytical column databases, in-memory databases, mobile, machine learning or BigData systems, create an opportunity to speed up analysis and open new possibilities. Current data management processes utilizing ETL, require a lot of effort to change or process and are usually not suitable for an agile approach.
Architectural Landscape
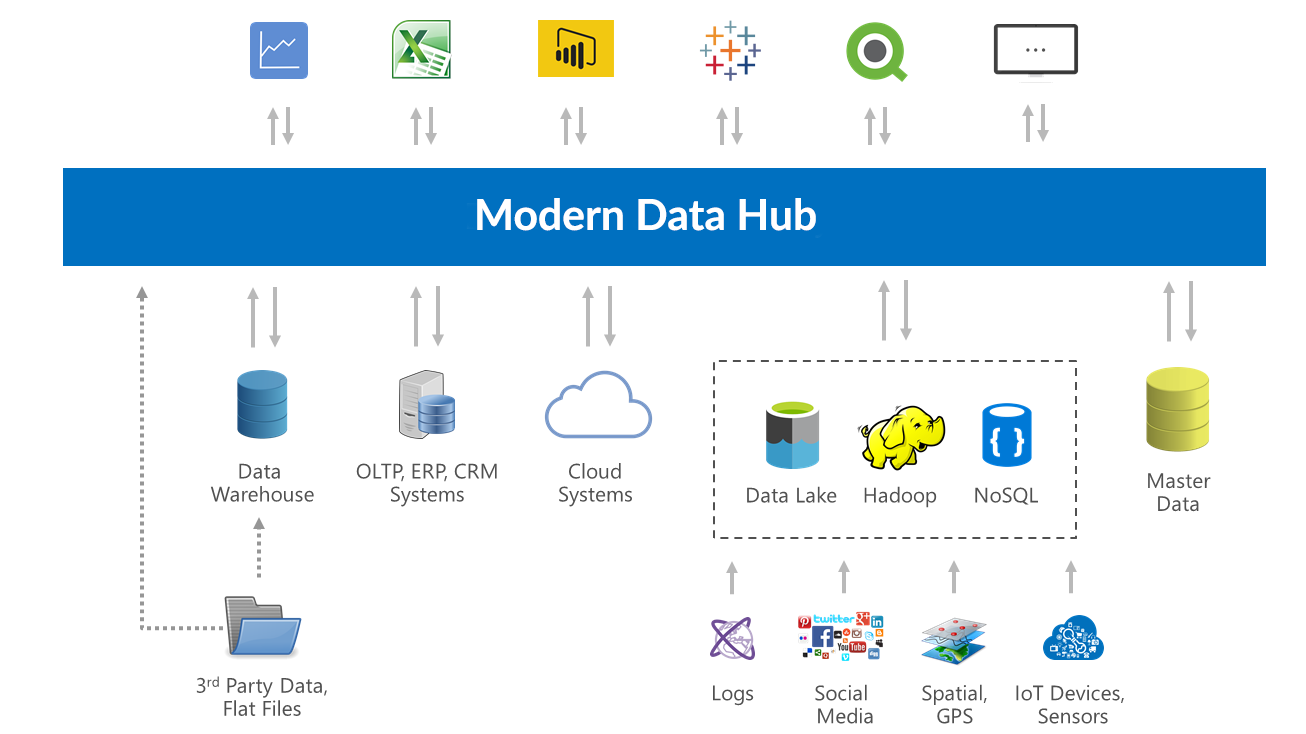
Modern Data Hub provides to data consumer an abstraction layer that hides most of the technical aspects of how and where data is stored, processed and how it's accessed. It allows accessing resources without delving into details like:
- where data resides,
- what technology or platform is used to store and process data, or
- what interfaces are needed to access data.
The following diagram depicts how Modern Data Hub is positioned on the architecture landscape.
Vision and goals
Lyftron's vision is to unleash the potential of Modern Data Hub and data federation technologies. Backed by BigData technology stack, to concurrently allow for high compatibility with existing technologies used for data access and analysis. And abstraction layer provided for all applications and data, helps to achieve flexibility for change, pervasive and consistent data access, and greatly reduced costs because of less need to create physically integrated data structures.
The end result is greater agility from, and freer access to, an organization’s data assets and promotion of self-service. Among other benefits, offer an opportunity for organizations to change and optimize the manner in which data is physically persisted, while not impacting the applications and business processes.
Lyftron's top goals are:
- Through Modern Data Hub enable customers to rapidly develop and deploy data services that access, federate, abstract, and deliver data on-premise and in the cloud
- Data efficiently delivered via established protocols and technologies can be reused on multiple projects, allowing to achieve agility
- Gain faster business insights by almost instant, access to all the data, in a customizable and secure way
- Respond faster to ever changing requirements of analytics and BI enabling 5-10 times shorter time to solution than traditional EDW
- Enable savings of 50-75% over data replication and consolidation.
| Support of | Lyftron's implementation |
|---|---|
| Any analitics client | Microsoft SQL Server emulation so any client can connect without additional configuration allowing for top level compatibility with existing solutions |
| Any execution engine | 10 data processing engines supported for caching, that can be used simultaneously and work as a single unit |
| Any data source | 100+ data source types supported out of the box |
| Any platform | Windows and soon Unix/Linux using .net core |
| Any deployment model | On-premise, Cloud, Hybrid |
| Any scale | MPP engines supported, Apache Spark BigData engine built-in and ready to use |
Technology
How Lyftron approaches its vision and goals from the technological standpoint:
- Provide a high performance columnar Modern Data Hub engine,
- Emulate most popular and successful enterprise-grade database engine on a protocol level, allowing for broad and fast adoption without additional changes to existing tools and infrastructure,
- Provide pure Modern Data Hub tool that is fully integrated with Microsoft technology stack,
- Take advantage of the fastest data processing engines on the market like Apache Spark and others, enabling users to easily switch engines and use them in parallel,
- Provide full web-based self-service and administration portal,
- Provide internal ETL pipeline that uses parallel columnar processing,
- Provide on-premise, cloud and hybrid deployment models.
Columnar processing
Lyftron is a columnar Modern Data Hub engine internally. Incoming rows are converted into columnar format, for high parallelism and high performance processing. Outgoing results are converted into rows for compatibility with the SQL Server protocol.
Microsoft SQL Server emulation
Lyftron's emulation of Microsoft SQL Server is implemented from scratch. It involves compatibility with the following:
- Tabular Data Stream network protocol as described in Microsoft TDS documentation
- Data types and conversions - all data types are normalized automatically into equivalent SQL Server data types
- Metadata model exposed by SQL Server, including metadata catalog, system views, stored procedures, and functions
- SQL dialect supported by SQL Server
- Procedural programming constructs: IF, WHILE, DECLARE
- Temporary tables (stored in-memory)
- Selected SQL session environment variables
- Security model supported by SQL Server
- Authentication using Windows Integrated Authentication and SQL Server Standard Authentication (Mixed Mode)
- Job scheduling model and accompanying stored procedures
Client tools connectivity to Lyftron
Microsoft SQL Server emulation allows any client utilizing Microsoft-supported data access technology to connect to Lyftron. Connectivity to Lyftron was verified using example tools and technologies listed below.
Analytical, reporting or development tools:
- Tableau
- PowerBI
- Qlik
- Targit
- Microsoft Office
- Microsoft SQL Server Management Studio
Data access technologies:
- ADO.Net
- JDBC
- OLE DB
- ODBC
Lyftron's connectivity to data sources
Out-of-the-box Lyftron can connect to over 100 data source types like relational, MPP, NoSQL, SaaS, CRM's, or Social Media. For a full list of providers please consult the list of built-in providers.
ETL pipeline
Comparing to classic, flow-based ETL tools, Lyftron implements ETL responsibilities differently. It is assumed that most of processing requirements can be expressed using SQL and Views.
- Virtual Databases are wrappers over a data source to provide direct access to data (no caching allowed), or created over one of 10 supported data processing engines, that may be used for data integration and caching.
- Views may depend on each other and blend data using full power of SQL language.
- Views created in Lyftron's virtual databases are materializable (aka. cachable).
- Many processing-engine dependent strategies can be utilized, for example in-memory caching or persistent caching using table rotation.
- SQL Server restrictions of so called "indexed views" do not apply to Lyftron.
Deployment model
Lyftron can be deployed using the following models:
- on-premise, using physical or virtual machine with Windows (server and desktop)
- in-cloud, PaaS
- hybrid (mixed), on-premise and cloud